MLSQL 支持引用第三方项目模块
MLSQL很早就支持模块化。用户可以在MLSQL脚本中引用自己项目中的文件,参看如下示例:
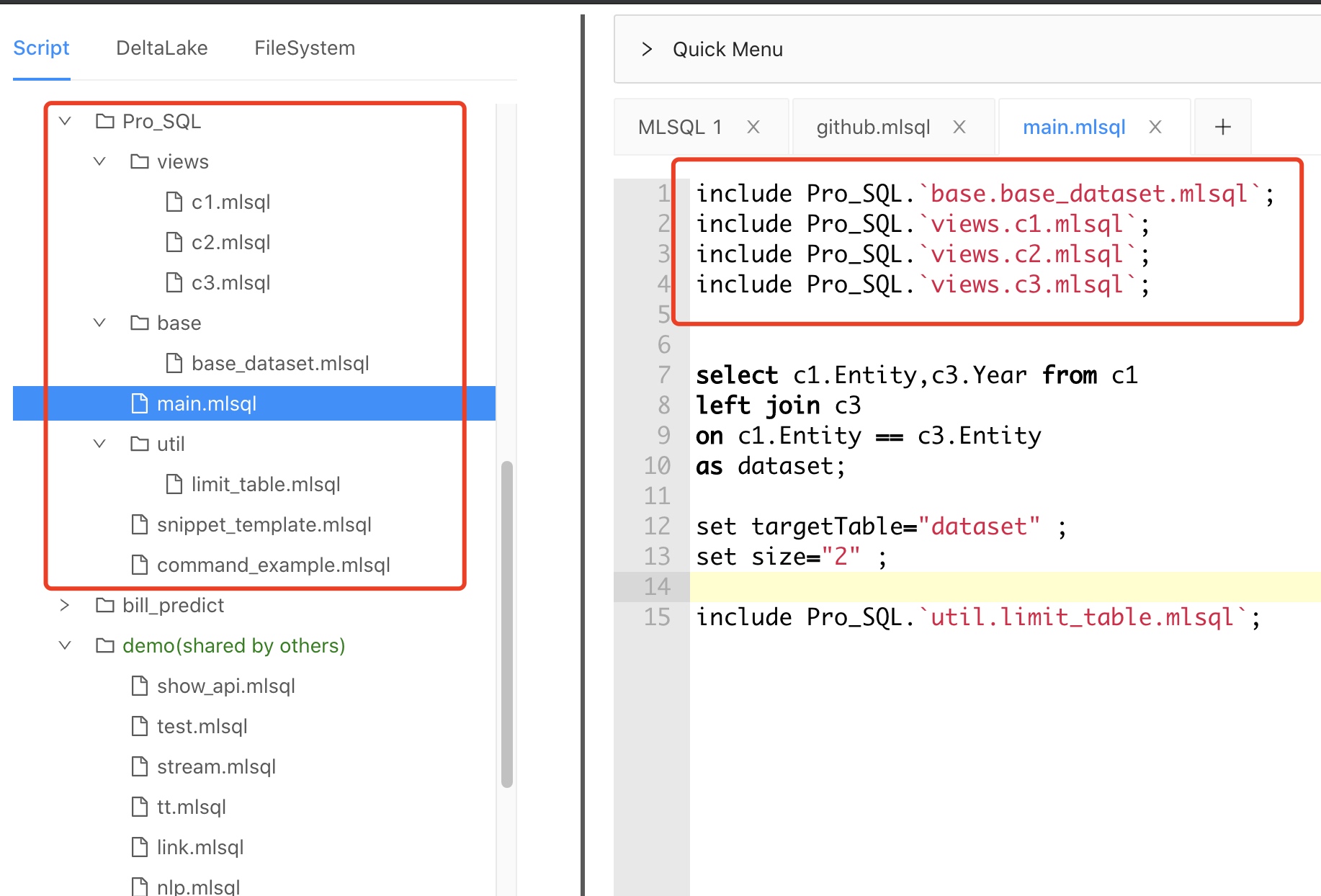
但是这种方式有个比较大的局限性,无法类似Java/Python等语言,形成强大的第三方开源库。为此,我们重新设计了MLSQL Mod,允许用户通过github分发自己基于MLSQL语言的库。设计参考MLSQL Mod设计。
通过Mod你可以分享什么?
MLSQL自身具有一定的编程能力,具体可参考这篇文章(内含视频链接):MLSQL:可编程的SQL,这意味着,你可以将如下的一些源码做成库分享给其他人:
- 常用的udf/udaf
- 使用Python完成的一些算法亦或是工具
- ETL/算法Pipeline
1,2比较好理解。3怎么理解呢?比如,用户使用MLSQL写了一个文本分类Pipeline,实现了端到端的训练,其他用户只要指定Schema的数据表,就可以进行训练从而得到模型输出,无需了解实现细节。
如何创建一个MLSQL Mod
目前创建MLSQL Mod非常简单。我这里开发了一个叫mlsql-example的模块。 唯一硬性要求是有一个package.json文件。一个典型的package.json文件如下:
{
"version": "1.0",
"main": "",
"init": "",
"pythonDeps":[
{
"name":"xlsxwriter",
"version":"==1.2.0"
},
{
"name":"xlrd",
"version":"==1.2.0"
}
],
"deps":[
{
"name":"github.com/allwefantasy/lib-util",
"version":"625643d21187ff486c58579161182c9414ec71ec"
}
]
}
在这里,我们指明这个模块需要依赖哪些Python库,以及其他MLSQL Mod依赖。现阶段系统不会检查python依赖,仅仅是方便使用模块的人进行查看,知道为了运行该模块,需要有哪些库。
接着就可以开始编写一些工具脚本了。我这里做了两个例子。一个是pkg/util/limit_table.mlsql, 该脚本的功能很简单,就是通过SQL做输出条数控制:
-- include script in the same project please use project name.
include local.`github.com/allwefantasy/mlsql-example.pkg.util.params`;
select * from ${targetTable} limit ${size} as output;
我们看到,该脚本还引用了 pkg/util/params.mlsql, 引用项目自身文件,需要使用项目名+包名。项目名为:github.com/allwefantasy/mlsql-example,包名为:pkg.util.params.
之后我们把项目发布到github上,现在就可以在任意地方进行引用了,使用方式如下:
-- import lib
include lib.`github.com/allwefantasy/mlsql-example`
where
-- commit="8b5a0ea7842733115f73c7748c10fb010af46537" and
alias="example";
-- load data
load delta.`python_data.vega_datasets`
as vega_datasets;
-- use script in mlsql-example to process table.
set targetTable="vega_datasets" ;
set size="1" ;
include local.`example.pkg.util.limit_table`;
我们看到,引用一个第三方库,也是使用include语法,我们可以给mod取别名以及指定某个commit。
接着通过include指定具体引用哪个脚本即可,这引用过程中,我们可以通过别名而非全名进行引用。
Python保存excel模块示例
有的时候我们要输出特别复杂的excel,这种情况,我们可能需要些python来进行一些定制。我在mlsql-example下提供了一个叫pkg/util/excel的工具,可以读写excel。以保存为例,
-- force="true" 表示每次运行时强制到github上更新Mod
include lib.`github.com/allwefantasy/mlsql-example`
where
force="true" and
alias="example";
load delta.`python_data.vega_datasets`
as vega_datasets;
-- 使用第三方库计算
set targetTable="vega_datasets" ;
set excelPath="/tmp/vega_datasets.xlsx";
include local.`example.pkg.util.excel.write`;
!hdfs -ls /tmp;
执行完成后就可以看到生成的excel文件了:

对应的pkg/util/excel/write源码在这里:pkg/util/excel/write.mlsql
我们写了一段简单的python代码对指定的数据集进行处理,然后生成excel。现在任何人都可以通过mod引入到自己的脚本中,从而完成excel的处理。
总结
通过MLSQL Mod机制,我们现在可以很方便把我们的MLSQL代码打包分享出来。未来,结合MLSQL插件机制,我们可以使用Java/Scala开发核心功能,之后再通过MLSQL脚本进行包装,从而完成更加复杂的功能需求。