MLSQL深度学习入门【二】-分布式模型训练
本文所有代码示例都基于MLSQL Engine最新版本 2.1.0-SNAPSHOT
本文将使用MLSQL Console的notebook演示深度学习的Hello world示例-mnist数据集。
环境要求、数据准备请参考前一篇: MLSQL深度学习入门【一】。
系列文章:
- MLSQL 机器学习最简教程(无需Python!)
- MLSQL深度学习入门【一】
- MLSQL深度学习入门【二】-分布式模型训练
- MLSQL深度学习入门【三】-特征工程
- MLSQL深度学习入门【四】-Serving
我们会继续使用上一篇的数据集。
注意,在本文中,Ray环境是必选项
加载数据
我们可以在MLSQL Console的notebook里按如下方式加载数据:
load parquet.`/tmp/mnist` as mnist;
Python环境配置
接着需要指定Python Client在Driver端,并且选择相应的环境。因为我们从Python得到输出是模型目录,所以指定schema为file即可。对于非ETL,dataMode 都设置为model。
!python env "PYTHON_ENV=source /Users/allwefantasy/opt/anaconda3/bin/activate ray1.3.0";
!python conf "runIn=driver";
!python conf "schema=file";
!python conf "dataMode=model";
基础概念
现在,我们可以开始写python代码了,代码大概长这个样子:
第一步,我们还是需要在notebook的cell里提供下该cell的语言类型,数据表,以及是否需要缓存等信息。具体而言,就是下面的Annotation:
--%python
--%input=mnist
--%cache=true
--%output=mnist_model
接着,我们需要获取ray_context会话对象,方式如下:
ray_context = RayContext.connect(globals(),"127.0.0.1:10001")
该对象可以帮助我们在Python中获取数据和输出数据。在这里,我们指定了数据是mnist表,也就是前面通过load语法加载的表。我们可以通过下面的代码获得每个数据分区的引用:
data_servers = ray_context.data_servers()
data_servers 是一个数组。数组的长度就是分区的数目。
replica_num = len(data_servers)
print(f"total workers {replica_num}")
我们会在接下来的代码中,启动replica_num个TF Worker 去分布式训练我们的模型。
模型和分片数据
我们会使用上次的模型,他的样子大概是这样的:
def create_tf_model():
network = models.Sequential()
network.add(layers.Dense(512,activation="relu",input_shape=(28*28,)))
network.add(layers.Dense(10,activation="softmax"))
network.compile(optimizer="sgd",loss="categorical_crossentropy",metrics=["accuracy"])
return network
接着,我们可以通过下面的方法获取任意一个分区的数据:
def data_partition_creater(data_server):
temp_data = [item for item in RayContext.collect_from([data_server])]
train_images = np.array([np.array(item["image"]) for item in temp_data])
train_labels = np_utils.to_categorical(np.array([item["label"] for item in temp_data]) )
train_images = train_images.reshape((len(temp_data),28*28))
return train_images,train_labels
在本文中,我们会使用Actor 来创建TF worker来完成分布式训练。Actor的数量取决于数据分区的数量。
创建 TF Worker
我们将会使用Ray的Actor来构建Worker,然后使用的Parameter Server的模式来进行训练。
Worker定义代码如下:
@ray.remote
class Network(object):
def __init__(self,data_server):
self.model = create_tf_model()
# you can also save the data to local disk if the data is
# not fit in memory
self.train_images,self.train_labels = data_partition_creater(data_server)
def train(self):
history = self.model.fit(self.train_images,self.train_labels,batch_size=128)
return history.history
def get_weights(self):
return self.model.get_weights()
def set_weights(self, weights):
# Note that for simplicity this does not handle the optimizer state.
self.model.set_weights(weights)
def get_final_model(self):
model_path = os.path.join("/","tmp","minist_model")
self.model.save(model_path)
model_binary = [item for item in streaming_tar.build_rows_from_file(model_path)]
return model_binary
def shutdown(self):
ray.actor.exit_actor()
启动TF Worker
现在,根据数据分片的数量启动Worker(注意,这些Worker都是分布在Ray集群上的独立的进程):
workers = [Network.remote(data_server) for data_server in data_servers]
开始训练
先开始第一个Epoch训练来获取每个Worker所包含模型的参数:
ray.get([worker.train.remote() for worker in workers])
_weights = ray.get([worker.get_weights.remote() for worker in workers])
定义一个更新参数的方法:
def epoch_train(weights):
sum_weights = reduce(lambda a,b: [(a1 + b1) for a1,b1 in zip(a,b)],weights)
averaged_weights = [layer/replica_num for layer in sum_weights]
[worker.set_weights.remote(averaged_weights) for worker in workers]
ray.get([worker.train.remote() for worker in workers])
return ray.get([worker.get_weights.remote() for worker in workers])
现在可以进行训练了:
for epoch in range(6):
_weights = epoch_train(_weights)
你会看到如下日志:

返回模型
最后,调用随意选一个worker,保存下模型:
model_binary = ray.get(workers[0].get_final_model.remote())
关闭所有worker:
[worker.shutdown.remote() for worker in workers]
返回模型给系统:
ray_context.build_result(model_binary)
把模型保存到数据湖
save overwrite mnist_model as delta.`ai_model.mnist_model`;
输出如下:

完整Notebook如下
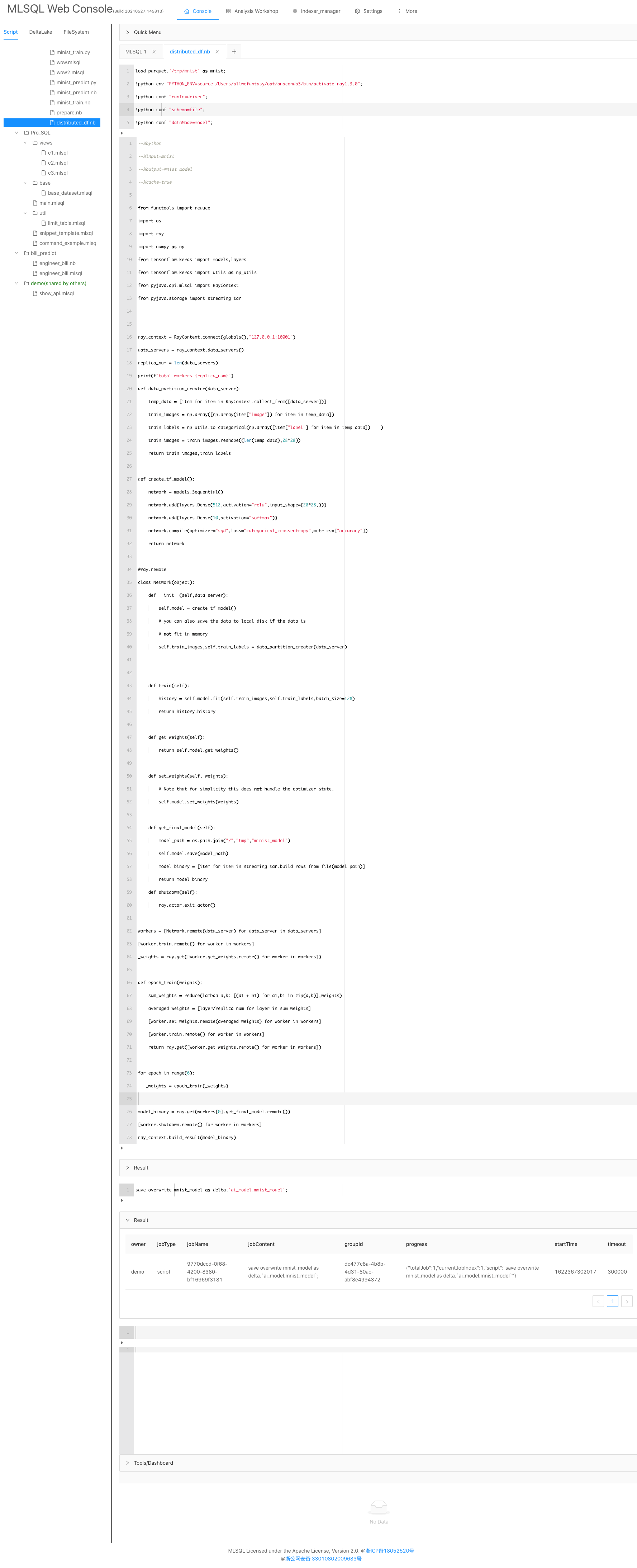
完整Python代码
--%python
--%input=mnist
--%output=mnist_model
--%cache=true
from functools import reduce
import os
import ray
import numpy as np
from tensorflow.keras import models,layers
from tensorflow.keras import utils as np_utils
from pyjava.api.mlsql import RayContext
from pyjava.storage import streaming_tar
ray_context = RayContext.connect(globals(),"127.0.0.1:10001")
data_servers = ray_context.data_servers()
replica_num = len(data_servers)
print(f"total workers {replica_num}")
def data_partition_creater(data_server):
temp_data = [item for item in RayContext.collect_from([data_server])]
train_images = np.array([np.array(item["image"]) for item in temp_data])
train_labels = np_utils.to_categorical(np.array([item["label"] for item in temp_data]) )
train_images = train_images.reshape((len(temp_data),28*28))
return train_images,train_labels
def create_tf_model():
network = models.Sequential()
network.add(layers.Dense(512,activation="relu",input_shape=(28*28,)))
network.add(layers.Dense(10,activation="softmax"))
network.compile(optimizer="sgd",loss="categorical_crossentropy",metrics=["accuracy"])
return network
@ray.remote
class Network(object):
def __init__(self,data_server):
self.model = create_tf_model()
# you can also save the data to local disk if the data is
# not fit in memory
self.train_images,self.train_labels = data_partition_creater(data_server)
def train(self):
history = self.model.fit(self.train_images,self.train_labels,batch_size=128)
return history.history
def get_weights(self):
return self.model.get_weights()
def set_weights(self, weights):
# Note that for simplicity this does not handle the optimizer state.
self.model.set_weights(weights)
def get_final_model(self):
model_path = os.path.join("/","tmp","minist_model")
self.model.save(model_path)
model_binary = [item for item in streaming_tar.build_rows_from_file(model_path)]
return model_binary
def shutdown(self):
ray.actor.exit_actor()
workers = [Network.remote(data_server) for data_server in data_servers]
ray.get([worker.train.remote() for worker in workers])
_weights = ray.get([worker.get_weights.remote() for worker in workers])
def epoch_train(weights):
sum_weights = reduce(lambda a,b: [(a1 + b1) for a1,b1 in zip(a,b)],weights)
averaged_weights = [layer/replica_num for layer in sum_weights]
ray.get([worker.set_weights.remote(averaged_weights) for worker in workers])
ray.get([worker.train.remote() for worker in workers])
return ray.get([worker.get_weights.remote() for worker in workers])
for epoch in range(6):
_weights = epoch_train(_weights)
model_binary = ray.get(workers[0].get_final_model.remote())
[worker.shutdown.remote() for worker in workers]
ray_context.build_result(model_binary)