MLSQL 机器学习最简教程(无需Python!)
系列文章:
- MLSQL 机器学习最简教程(无需Python!)
- MLSQL深度学习入门【一】
- MLSQL深度学习入门【二】-分布式模型训练
- MLSQL深度学习入门【三】-特征工程
- MLSQL深度学习入门【四】-Serving
我们可以使用MLSQL轻易完成整个机器学习的Pipline,这包括:
- 加载数据
- 处理数据
- 模型训练(支持多组参数,模型版本等)
- 批量预测
- 模型评估
- 部署API服务
今天,让我们开始这个旅程吧。
首先,加载我们已经准备好的数据:
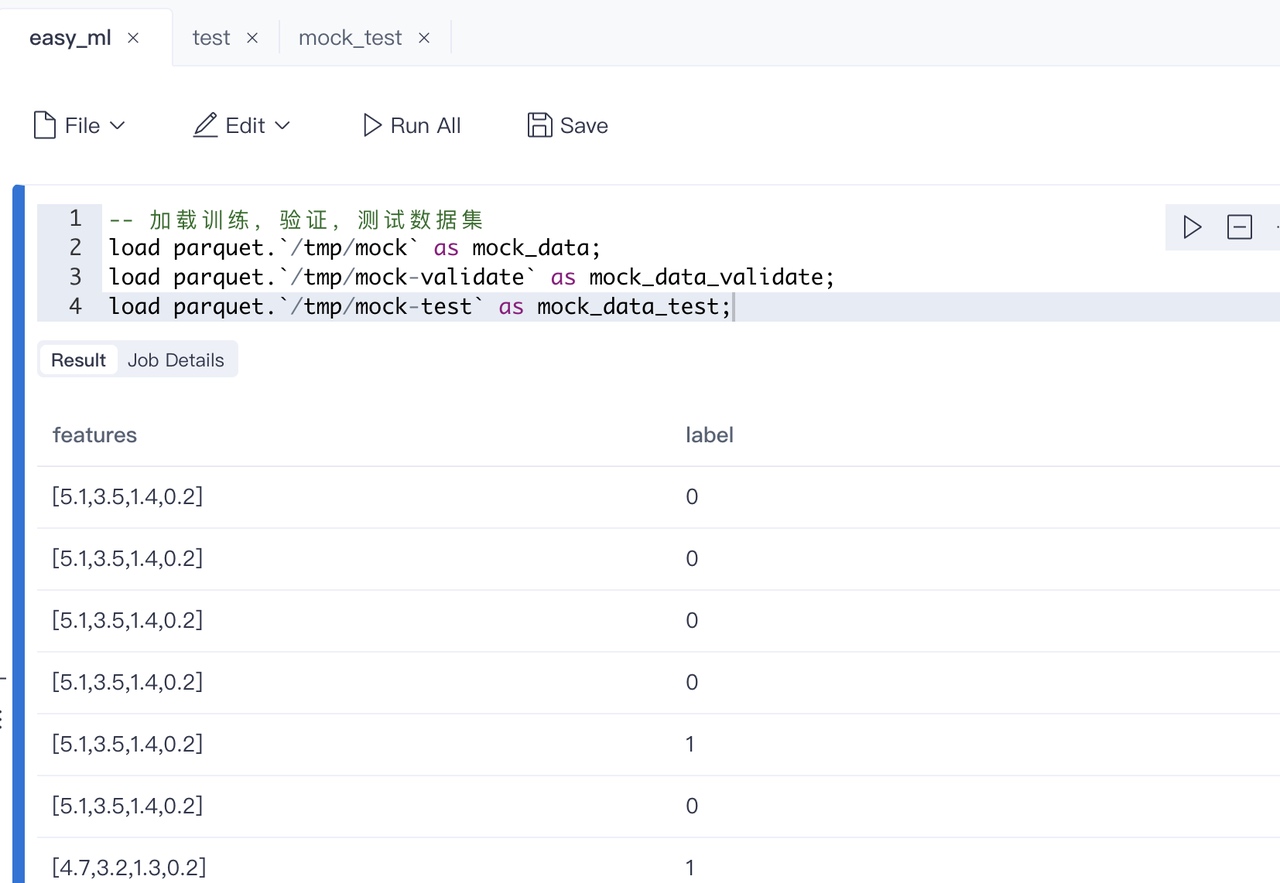
我们分别加载了训练数据,验证数据,和测试数据。因为原生是数组,需要转化为向量,所以简单做个转换:

因为这是个分类问题,所以我们需要选择一个分类算法。我们打算使用随机森林算法。不过我们首先要找找这个算法有没有:

我们用关键字 Random去检索,发现有的。但是我们现在还不知道这个模块怎么使用,所以我们可以借助下面的命令查看下:
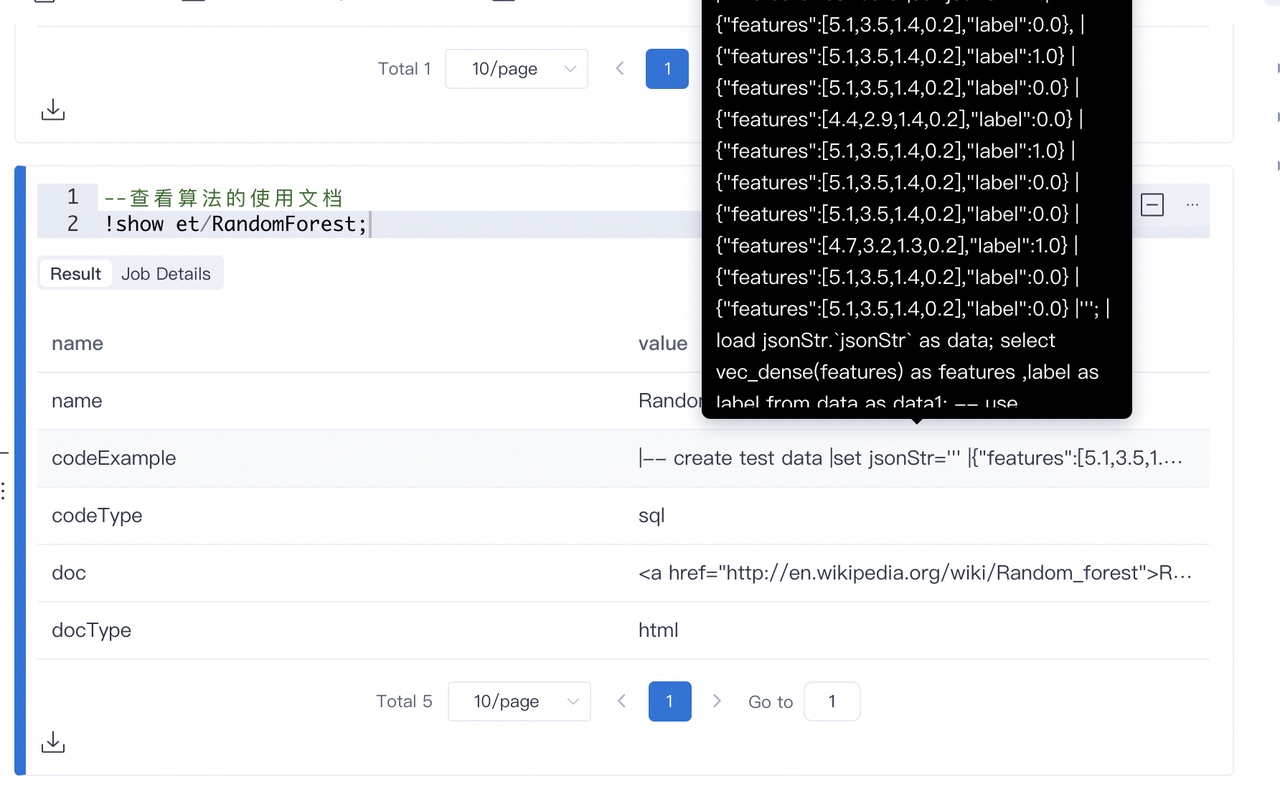
黑色部分是一个使用示例,doc部分展示该算法的一些介绍。我们依葫芦画瓢画瓢,写一个:
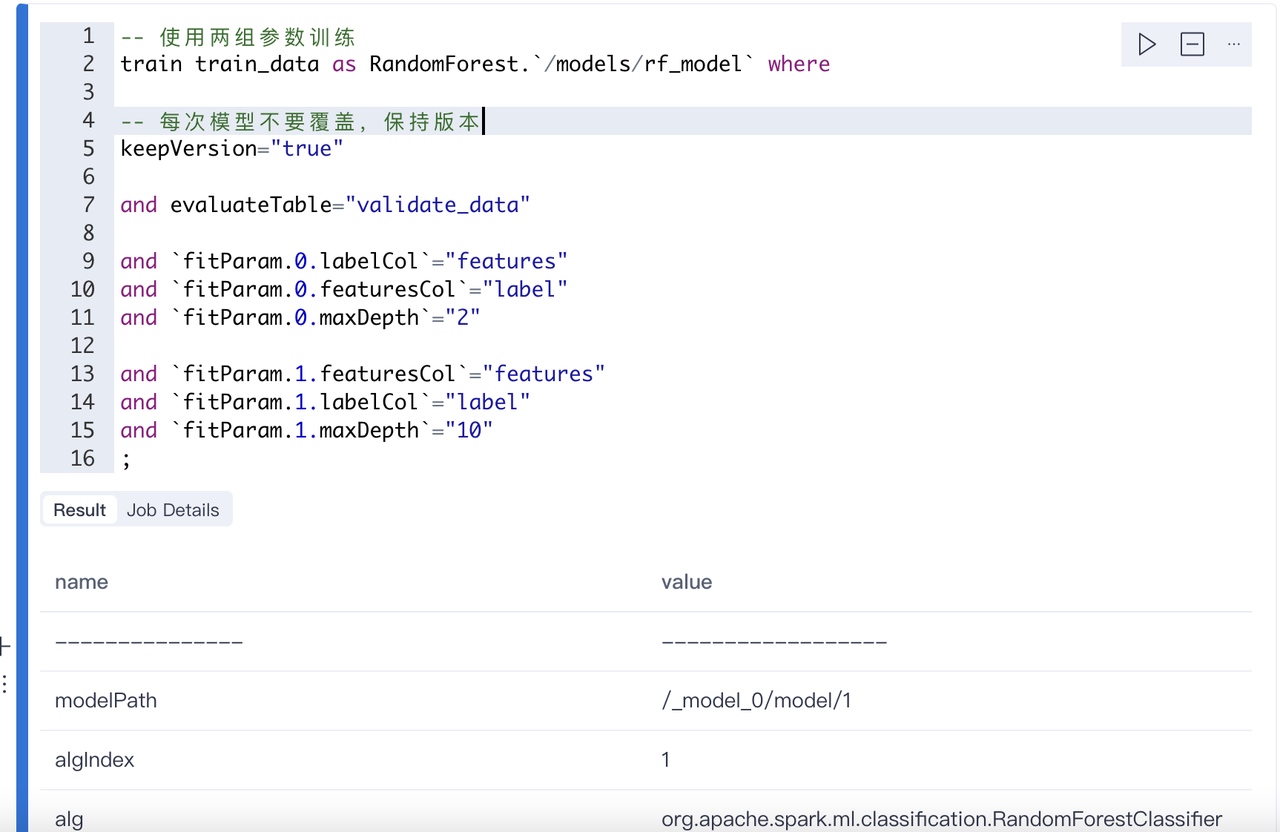
哦,对了,如果想看算法都有哪些参数,可以使用下面的指令进行查看:

我们配置了两组参数,系统会同时进行两个模型的训练,并且根据验证数据集算出那个效果更好。下面是完整的输出结果:
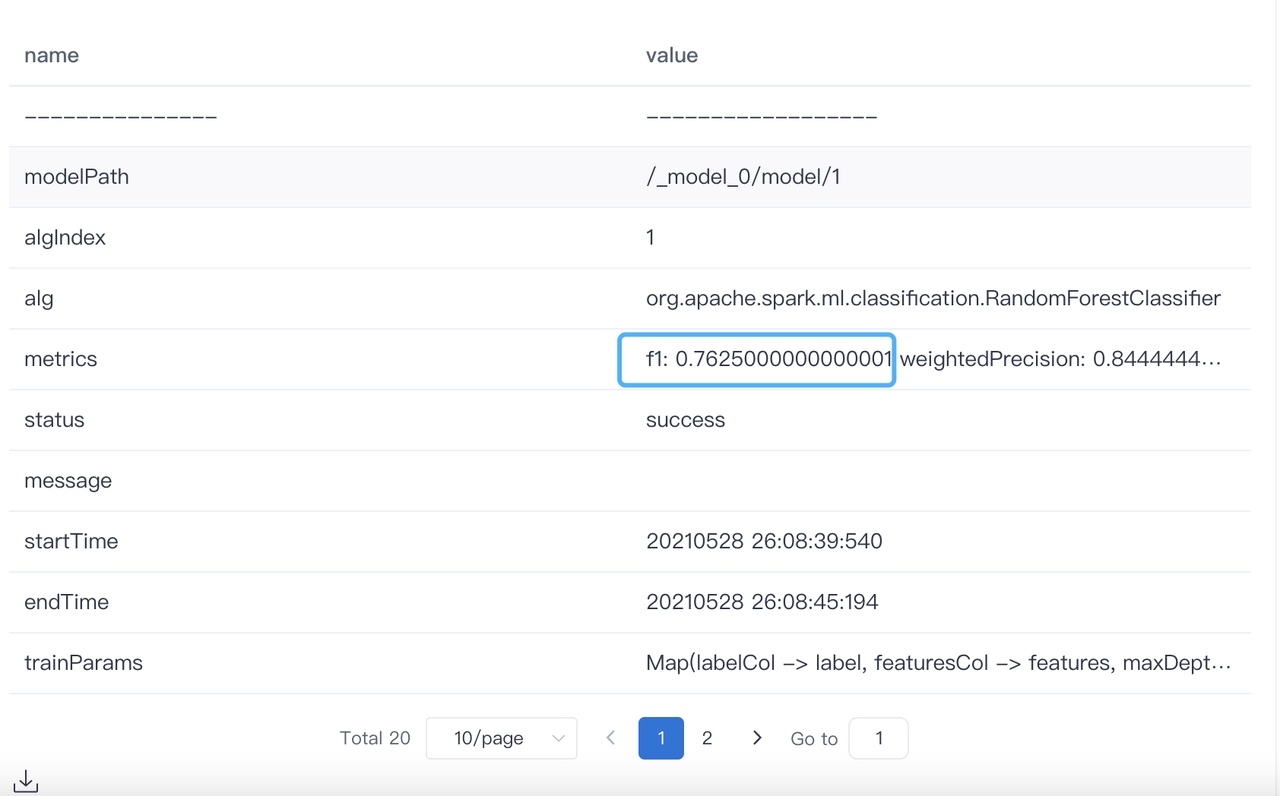
篮筐部分显示第二个模型的F1值(准确率)是76%。 假设我们接受了这个,然后我们需要拿我们还热乎的模型到测试数据集里去验证下效果,可以这么做:
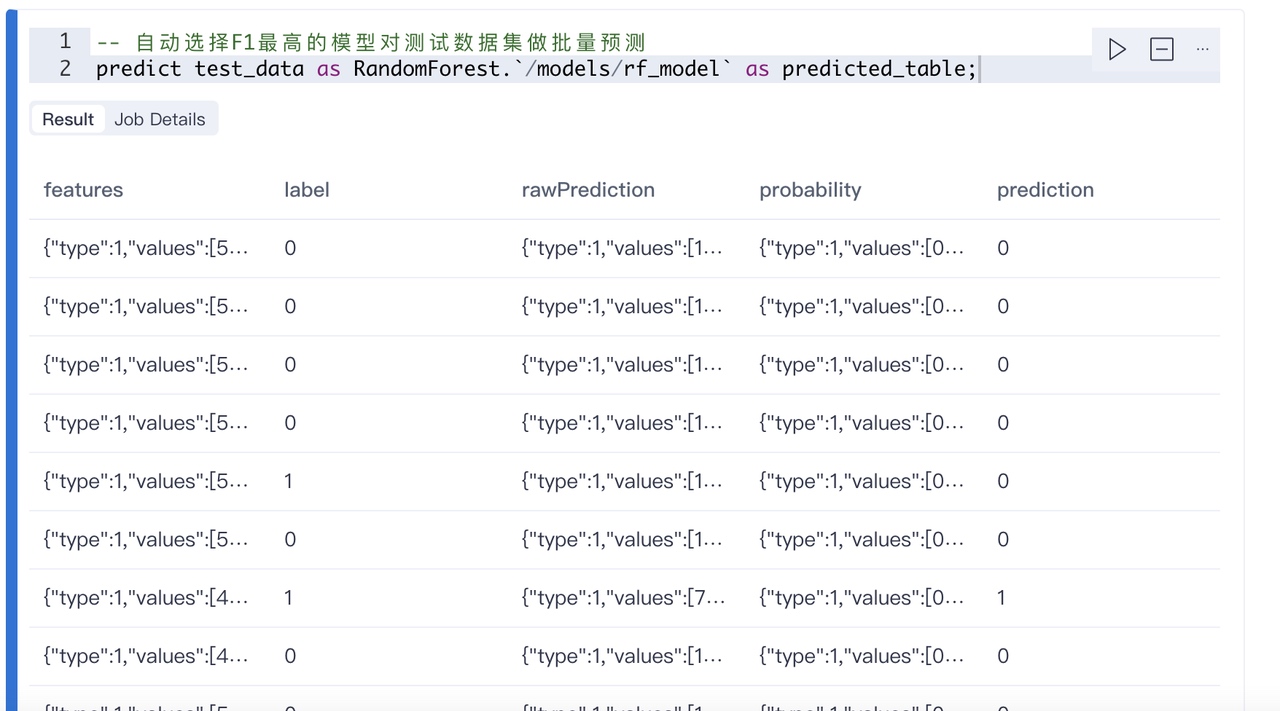
通过predict 指定数据集就可以了。现在只是看到了预测值(prediction),和实际的值(label),我们现在还不清楚对了多少,错了多少。我们用一个内置的模块来评估下:
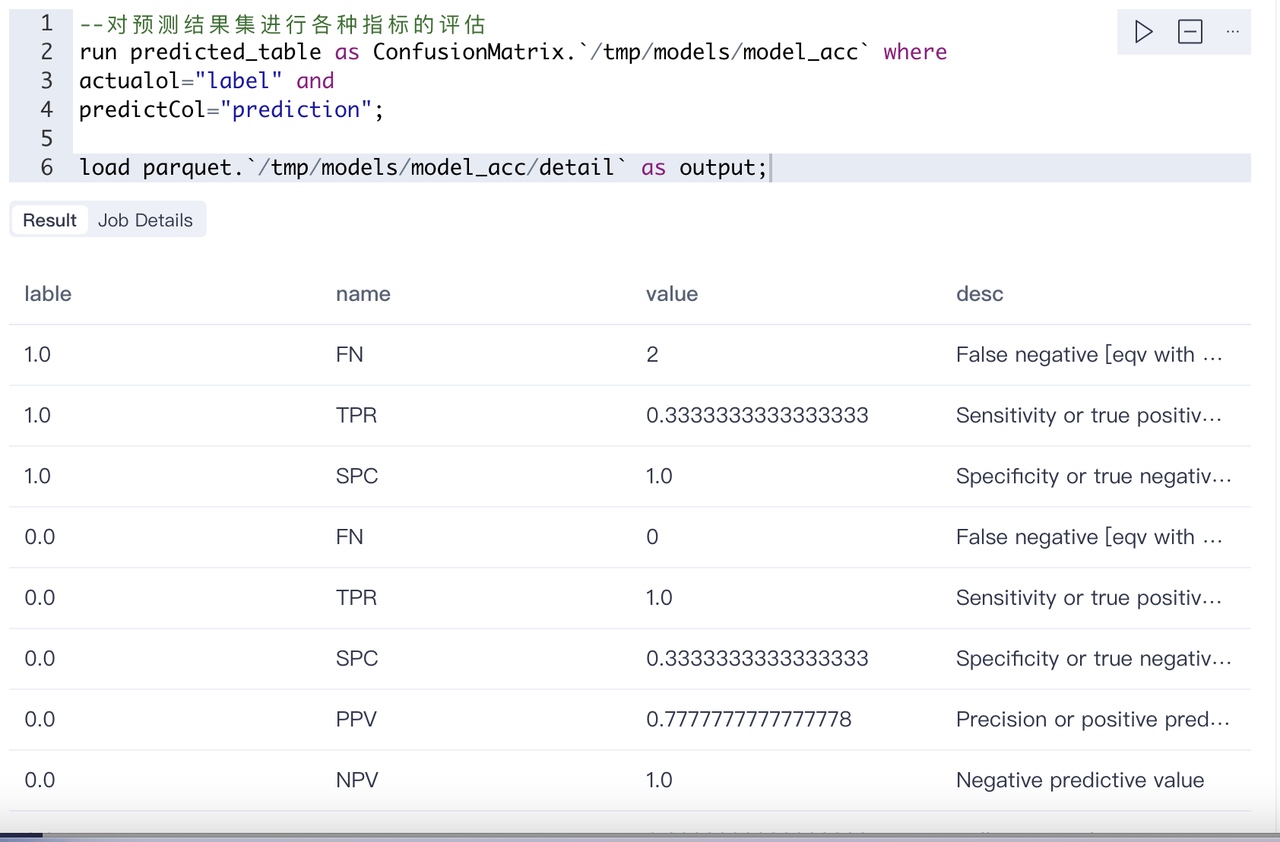
ConfusionMatrix会计算很多指标,比如PPV等,每个指标的含义在desc都有描述。一般我们关注的是准确率:

因为是2分类,所有有两个准确率。 效果都还不错达到了80%。
既然效果不错,那我们可以把模型部署到线上提供服务了。做法也很简单:
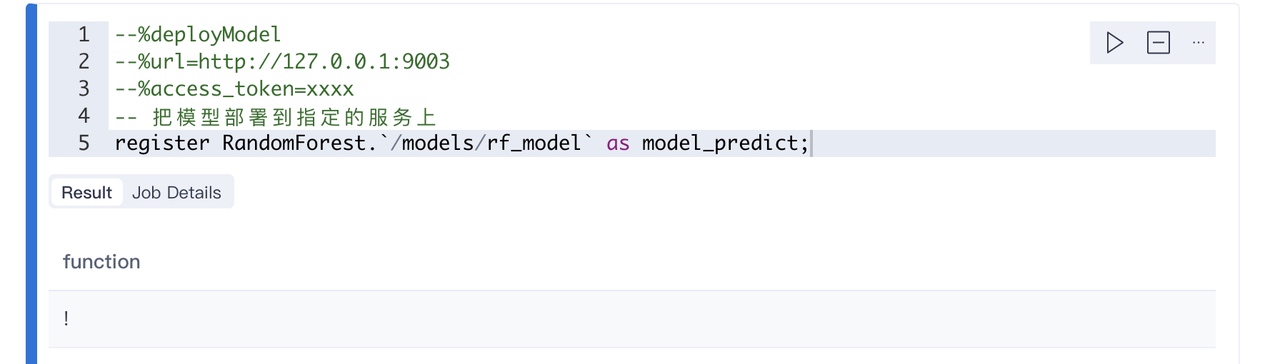
我们通过 deployModel 注解,然后通过register语法,把模型部署到指定的服务上。
现在我们可以通过调用http接口进行预测了:
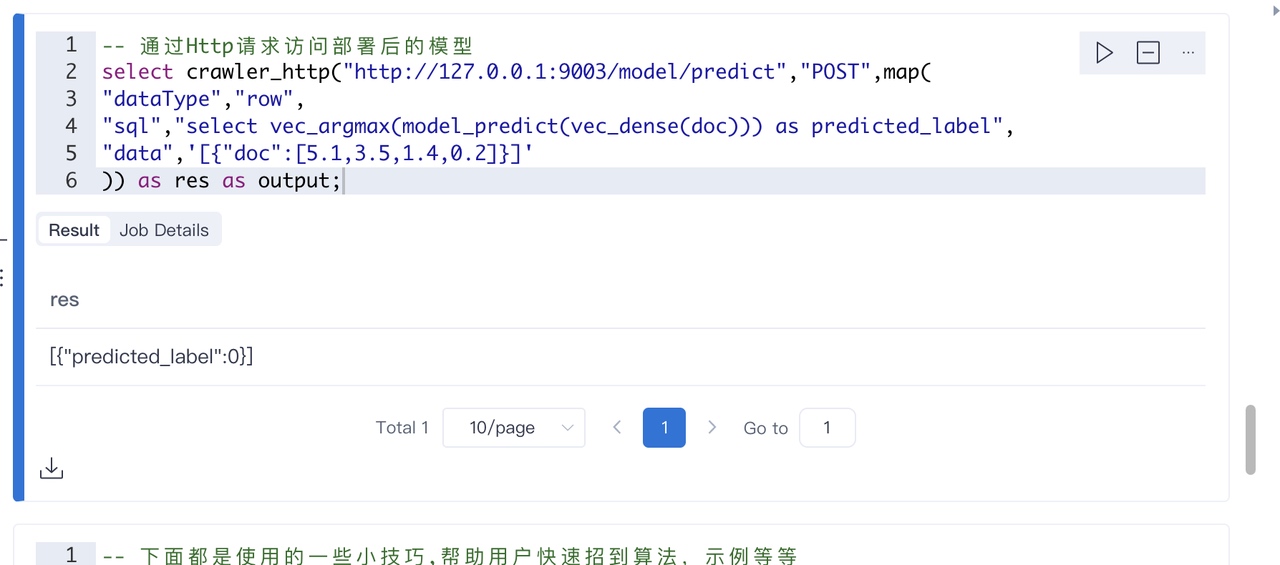
上面的语句相当于发起了一个POST请求。
Done,我们的模型已经在服务千家万户了。