【开脑洞】让MLSQL Engine一键变成调度系统
其实从某种角度,Spark挺适合做调度系统的。Driver 获取调度任务,任务的真正执行放到Executor里跑就行了。之前我在博文里提到,MLSQL Engine是一个以插件化内核,这意味着,你可以很方便的开发一个插件,让MLSQL Engine摇身一变变成调度系统。当然,我们这里开发的调度插件是和MLSQL Console强绑定的。
现在,让我们看看MLSQL Engine是如何支持调度的吧。
该插件目前不能应用于生产。等未来成熟了,强烈建议启动一个单独的MLSQL Engine专门作为调度系统。
开启
在启动MLSQL Engine的时候添加如下参数:
- -streaming.workAs.schedulerService=true
- --conf spark.mlsql.streaming.workAs.schedulerService.consoleUrl="http://127.0.0.1:9002"
- --conf spark.mlsql.streaming.workAs.schedulerService.consoleToken="mlsql"
其中第一个,第二个参数分别配置console的url地址和秘钥。因为调度系统需要通过Console获取的脚本内容和执行脚本。
这样,当你启动一个MLSQL Engine的时候,他已经可以作为调度引擎了。
如果把MLSQL Engine作为调度引擎,那么建议把元数据存储替换成MySQL,默认是数据湖。配置方式如下:
//meta store
-streaming.metastore.db.type="mysql",
-streaming.metastore.db.name="app_runtime_full",
-streaming.metastore.db.config.path="./__mlsql__/db.yml"
使用
秉承了MLSQL一切都应该用MLSQL语言来操作的理念,我们把调度设置抽象成了命令。
首先,我们在MLSQL Console里开发了一个脚本,具体内容如下:
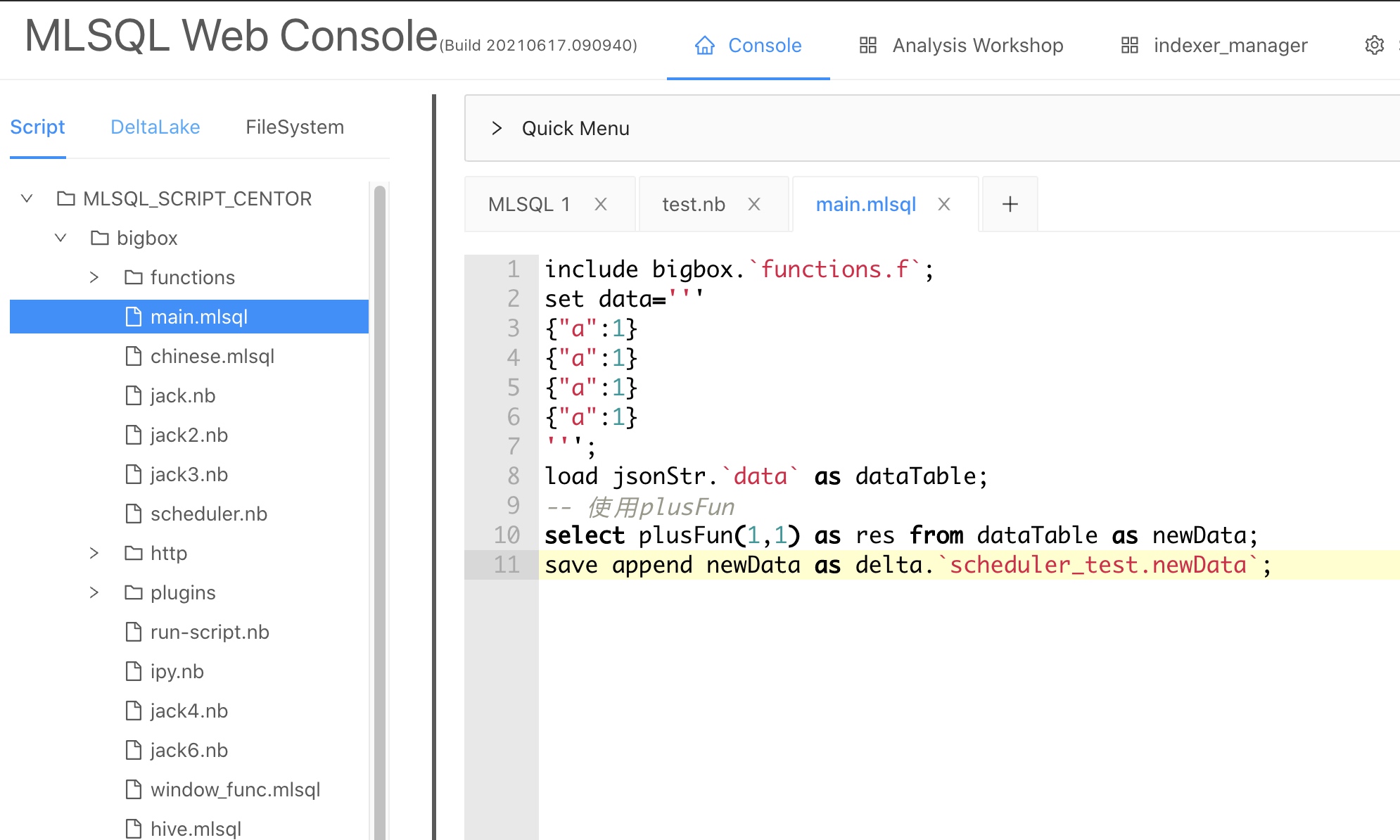
脚本内容很简单,使用一个自定义函数对数据做处理,处理结果添加到数据湖表scheduler_test.newData中。
现在我们希望定时执行这个脚本,为了方便演示,我们使用notebook模式。在演示中,我们希望一分钟执行一次这个脚本:
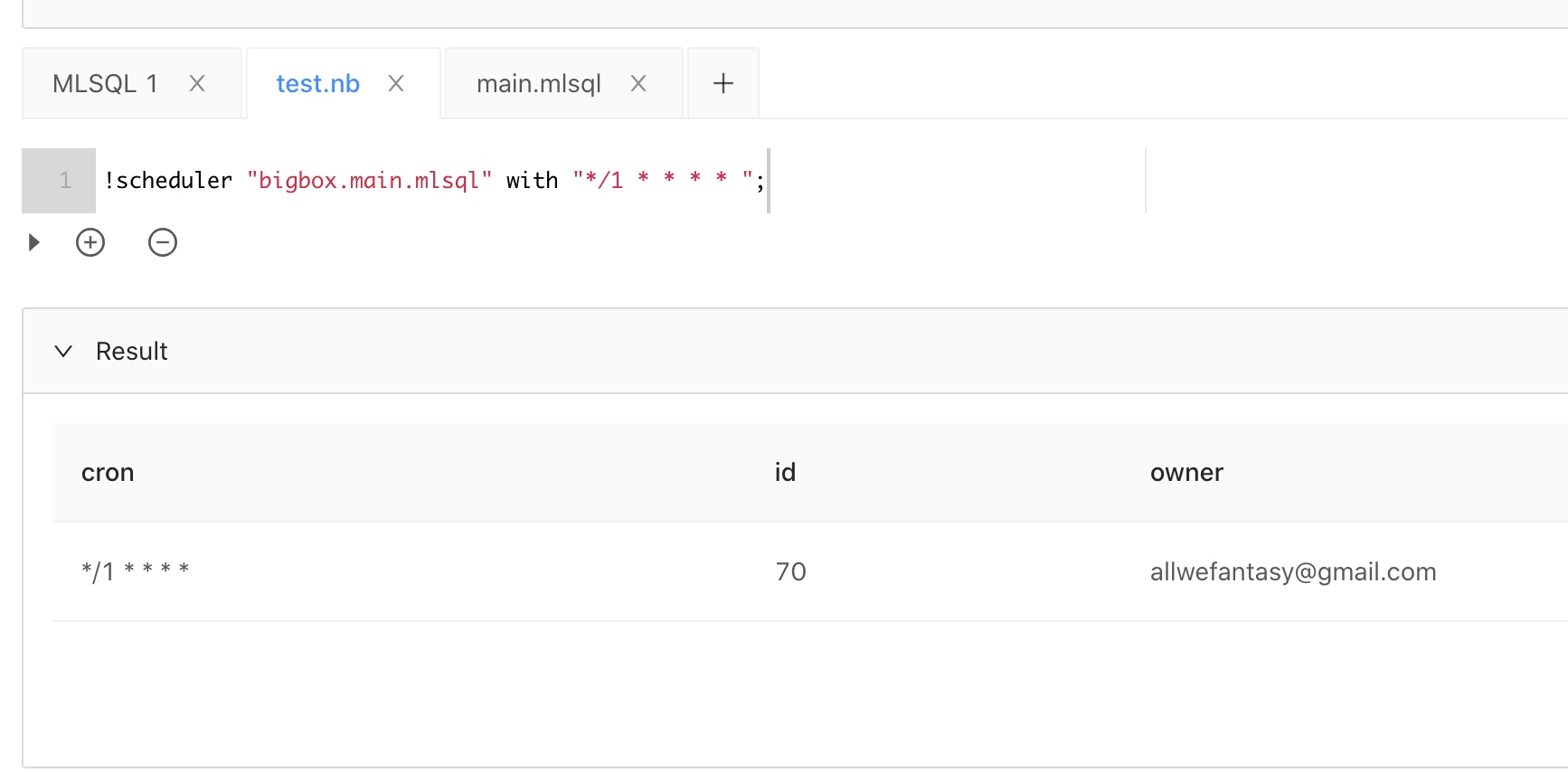
我们只要调用 !scheduler 命令即可。 with 后面是标准的cron语法。
等一会,我们查看下scheduler_test.newData表:
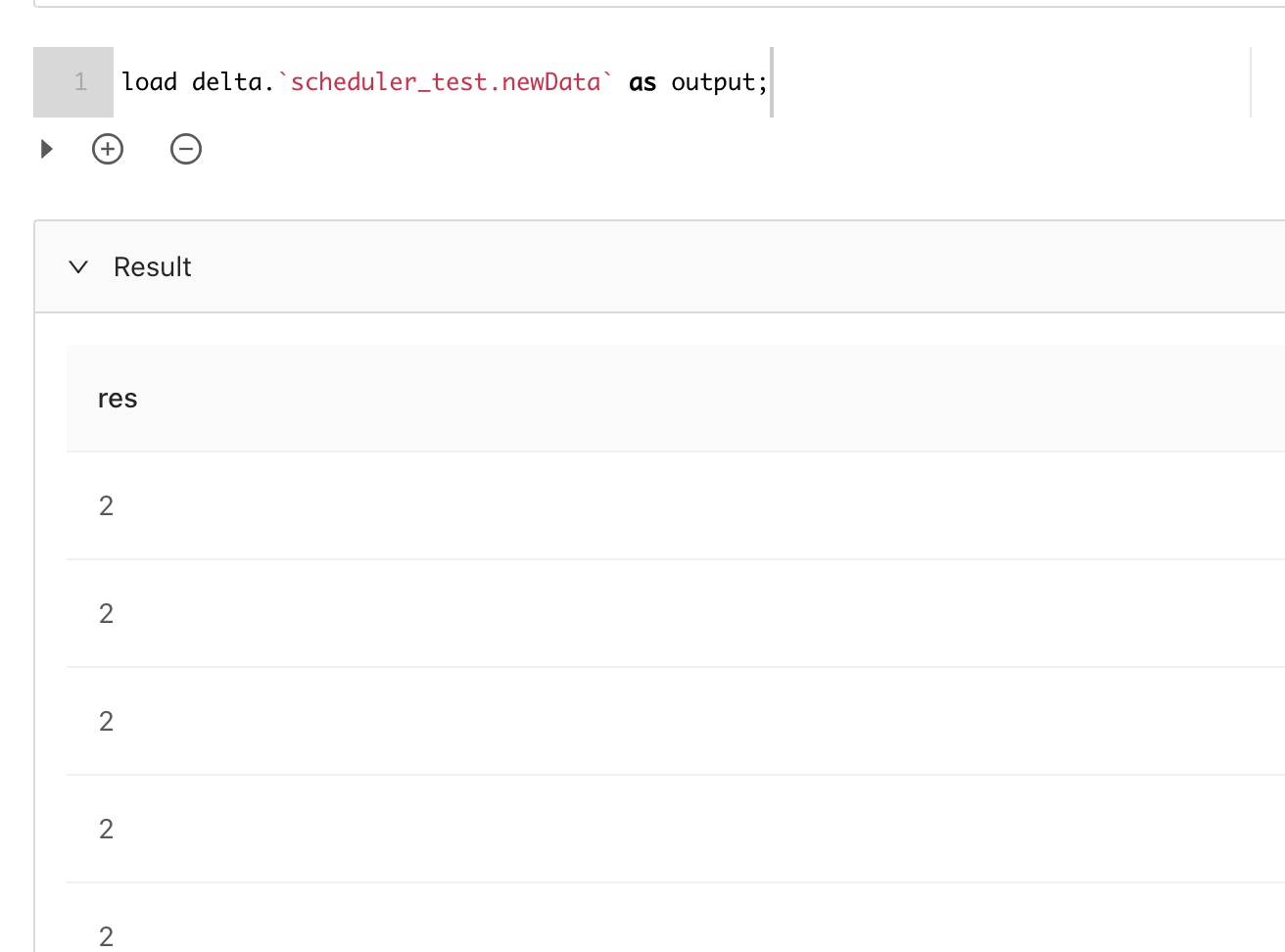
已经有数据了。
如果我想看下目前所有的定时任务,可以通过如下指令查看:

恩,确实只有一个。
那么支持依赖调度么?当然!如果我们希望执行完一个脚本后,执行另外一个脚本,可以使用如下语法:
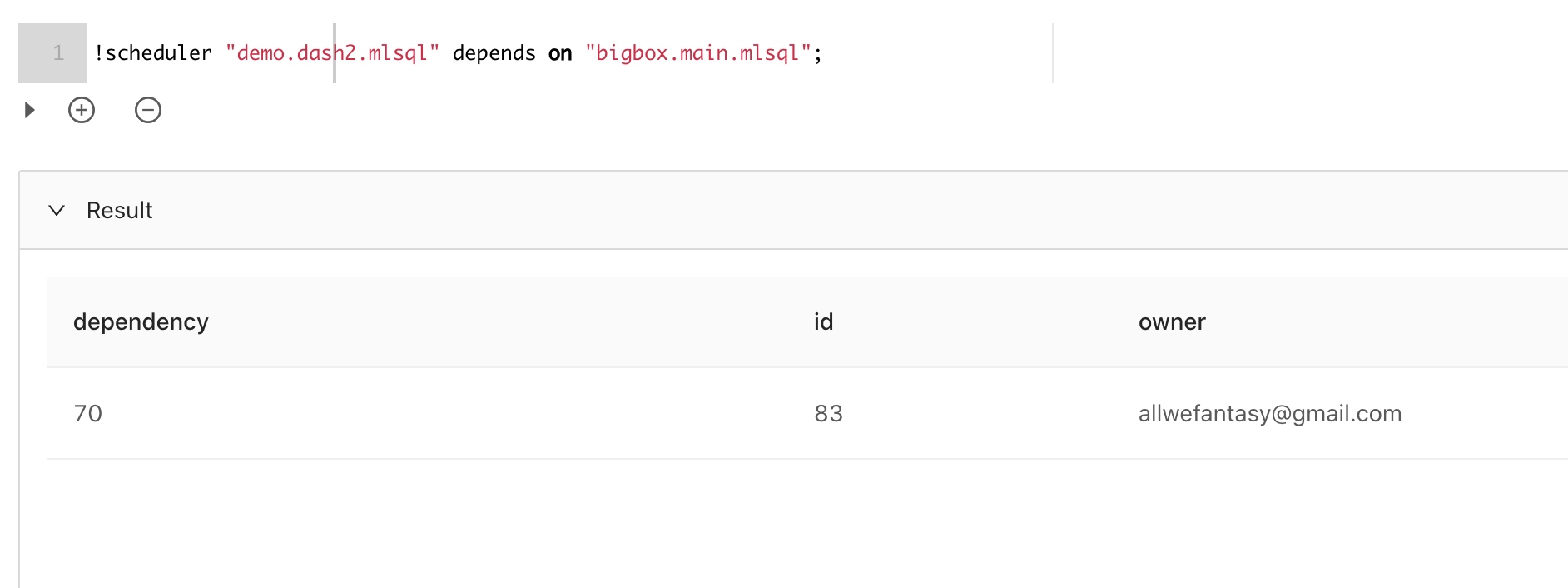
我们可以列出所有依赖任务:

如果希望移除任务,可以根据不同,可以分别按如下语法:
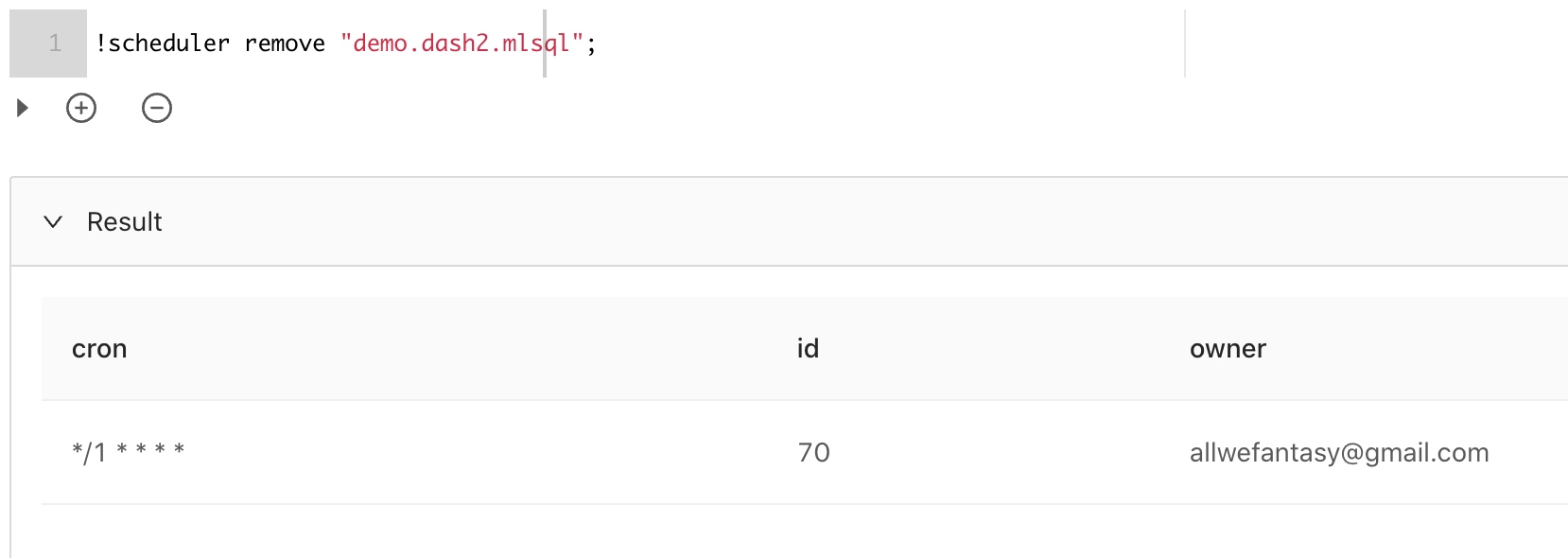
是不是很酷。
如何实现
前面我们说了,我们使用MLSQL插件机制来完成的,具体插件类型为这个:MLSQL插件开发系列2-引擎生命周期扩展点.
对于依赖任务核心是构建DAG依赖,我参考了TopoSortIndegree算法做了一个简单实现,具体实现类DAG
最后
目前该插件是内置插件,但还不能用于生产环境,仅能作为展示能力。我们未来希望能剥离成第三方插件,并且随着愈发成熟,慢慢能被使用。