MLSQL深度学习入门(三)-特征工程
本文所有代码示例都基于MLSQL Engine最新版本 2.1.0-SNAPSHOT
本文将使用MLSQL Console的notebook演示。
环境要求,请参考第一篇: MLSQL深度学习入门【一】。
系列文章列表:
- MLSQL 机器学习最简教程(无需Python!)
- MLSQL深度学习入门【一】
- MLSQL深度学习入门【二】-分布式模型训练
- MLSQL深度学习入门【三】-特征工程
- MLSQL深度学习入门【四】-Serving
本章,我们会介绍如何使用MLSQL对数据做特征工程。
值得注意的是:
- Ray 在本文中是必选项。
- cv2 需要保证Ray 每个节点都有安装。安装方式:
pip install opencv-python;
上传图片数据
这次,我们会使用cifar数据集。第一步是下载我放在github上的cifar数据集,下载到本地,解压,然后重新用tar 打包。打包好后。注意,一定是要tar包格式,然后就可以通过上传界面上传了:
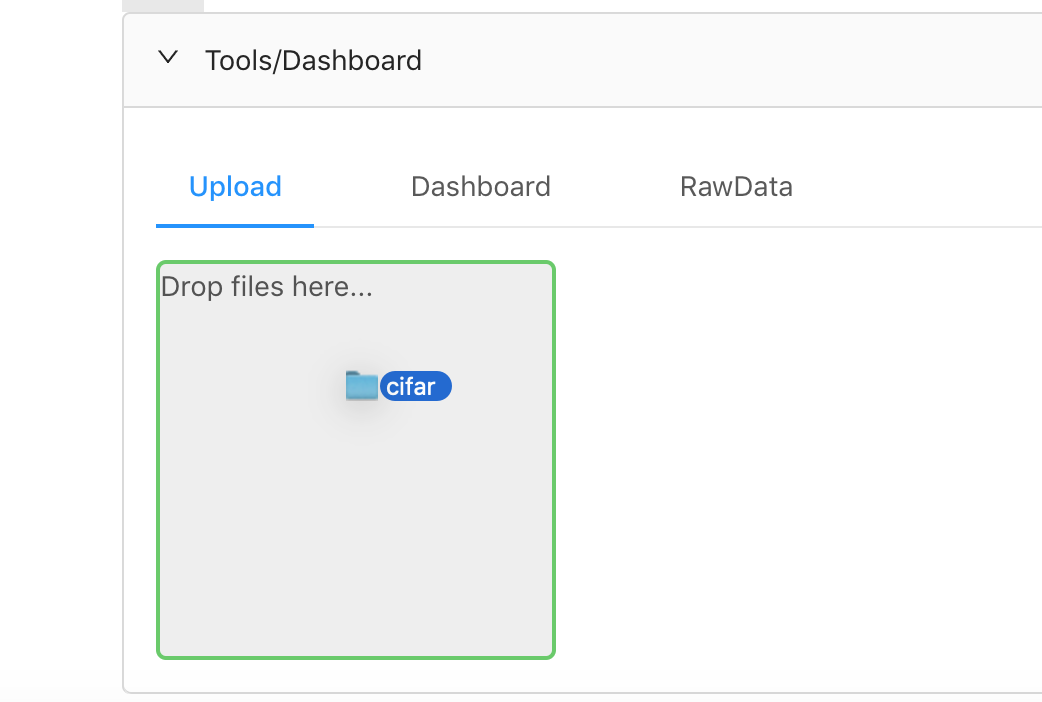
系统会自动解压tar包,所以我们通过命令可以看到图片已经在对象存储上了:
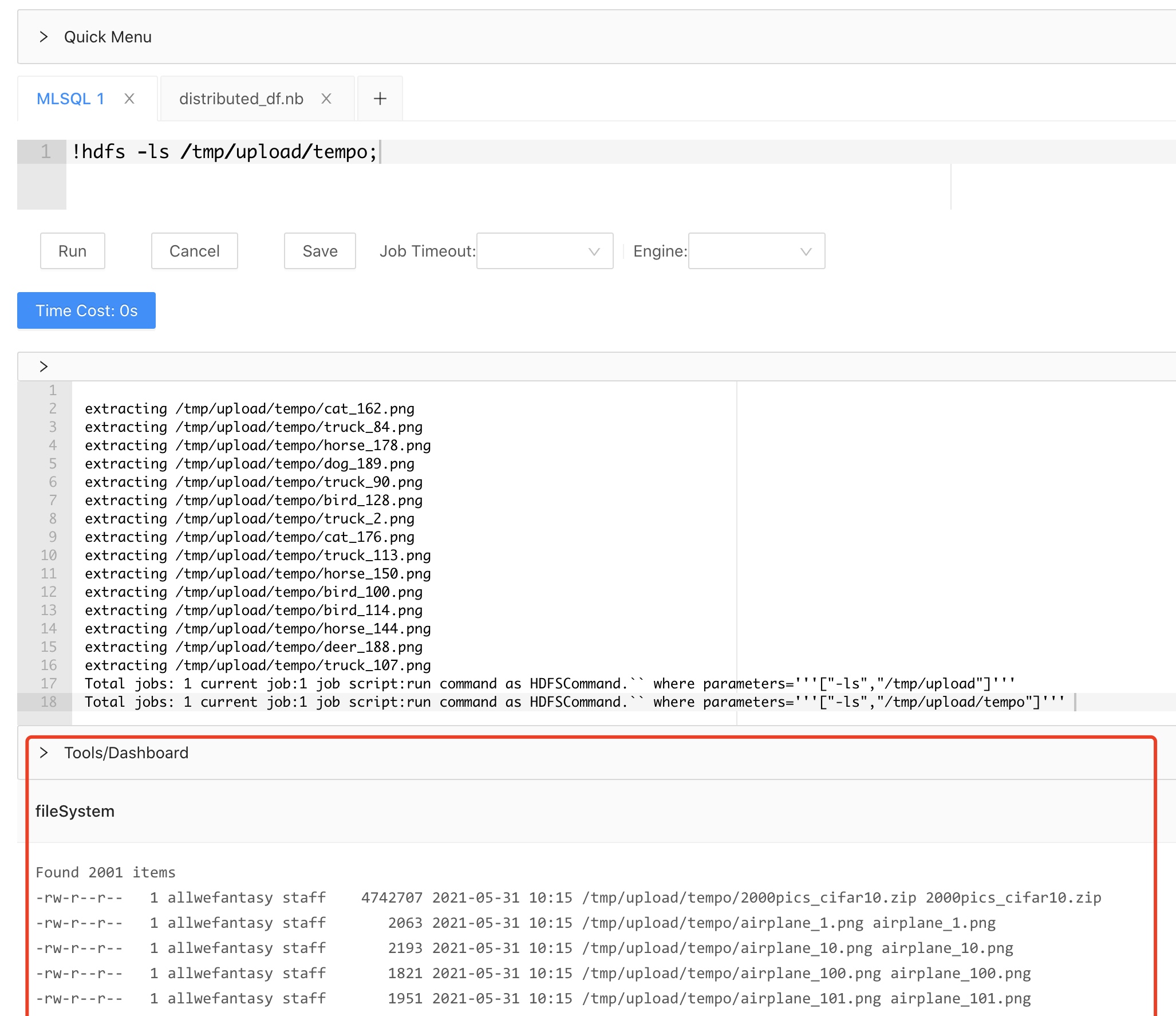
因为我打包的时候打包的是tempo目录(里面是cifar图片),所以大家看到的是tempo目录。
读取图片数据
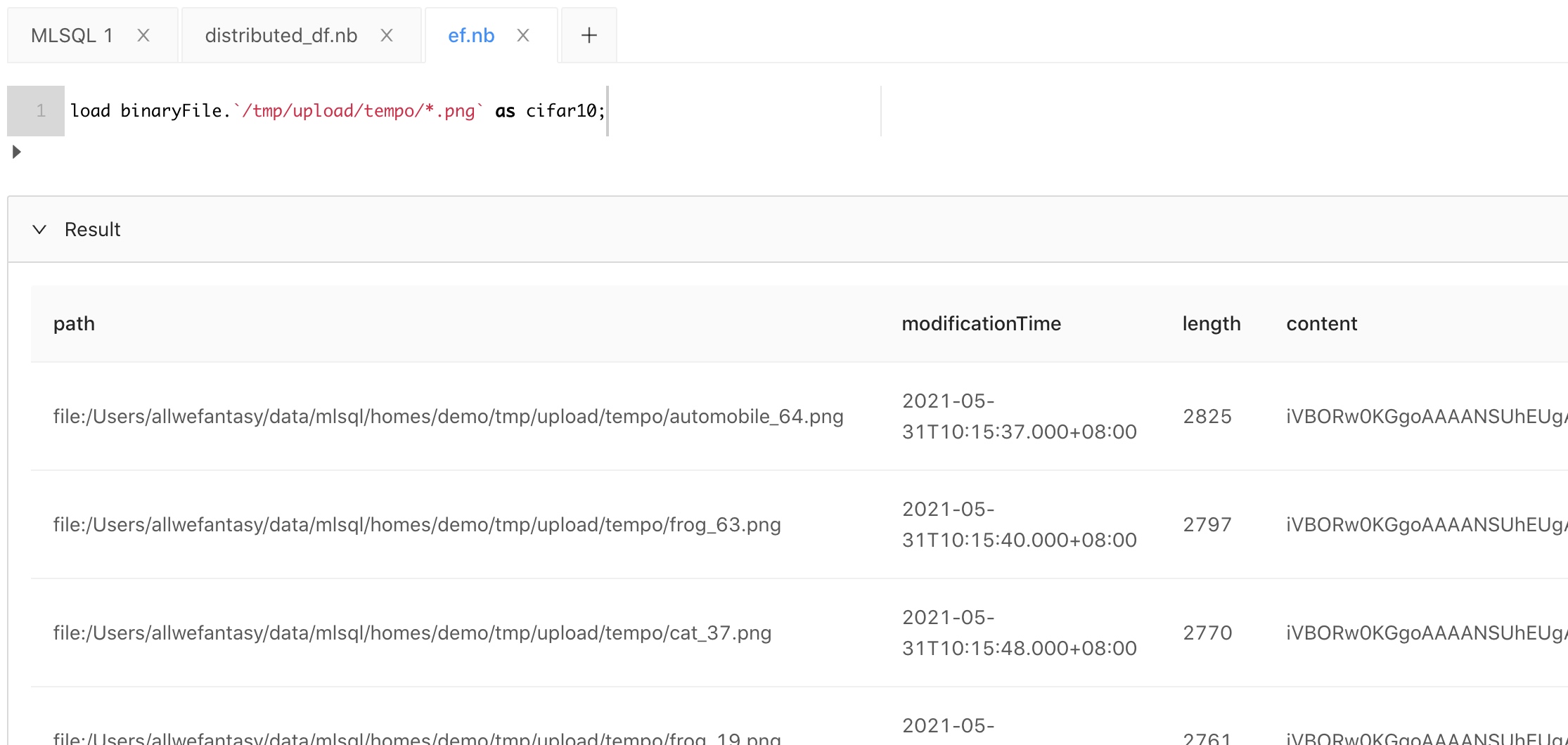
我们可以使用binary格式读取图片数据:
load binaryFile.`/tmp/upload/tempo/*.png` as cifar10;
结果如下:
处理图片
在MLSQL中,我们也是支持使用Python做ETL的。因为在很多场景,对于按行处理,有可能处理的逻辑比较复杂,SQL内置的UDF往往比较繁琐亦或是不能支持需求。尽管我们支持Scala自定义UDF,但显然用Python比Scala简单。
为此,我们提供了一种非常简单的方式使用Python来变相支持UDF,还能够支持按分区来处理数据。
为了增强算法的鲁棒性,我们需要会对图片做一些变换,旋转下图片亦或是把图片转化为统一大小等。在本文中,我们会把图片尺寸统一缩小为28*28。在此之前,我们先看看当前表的schema:
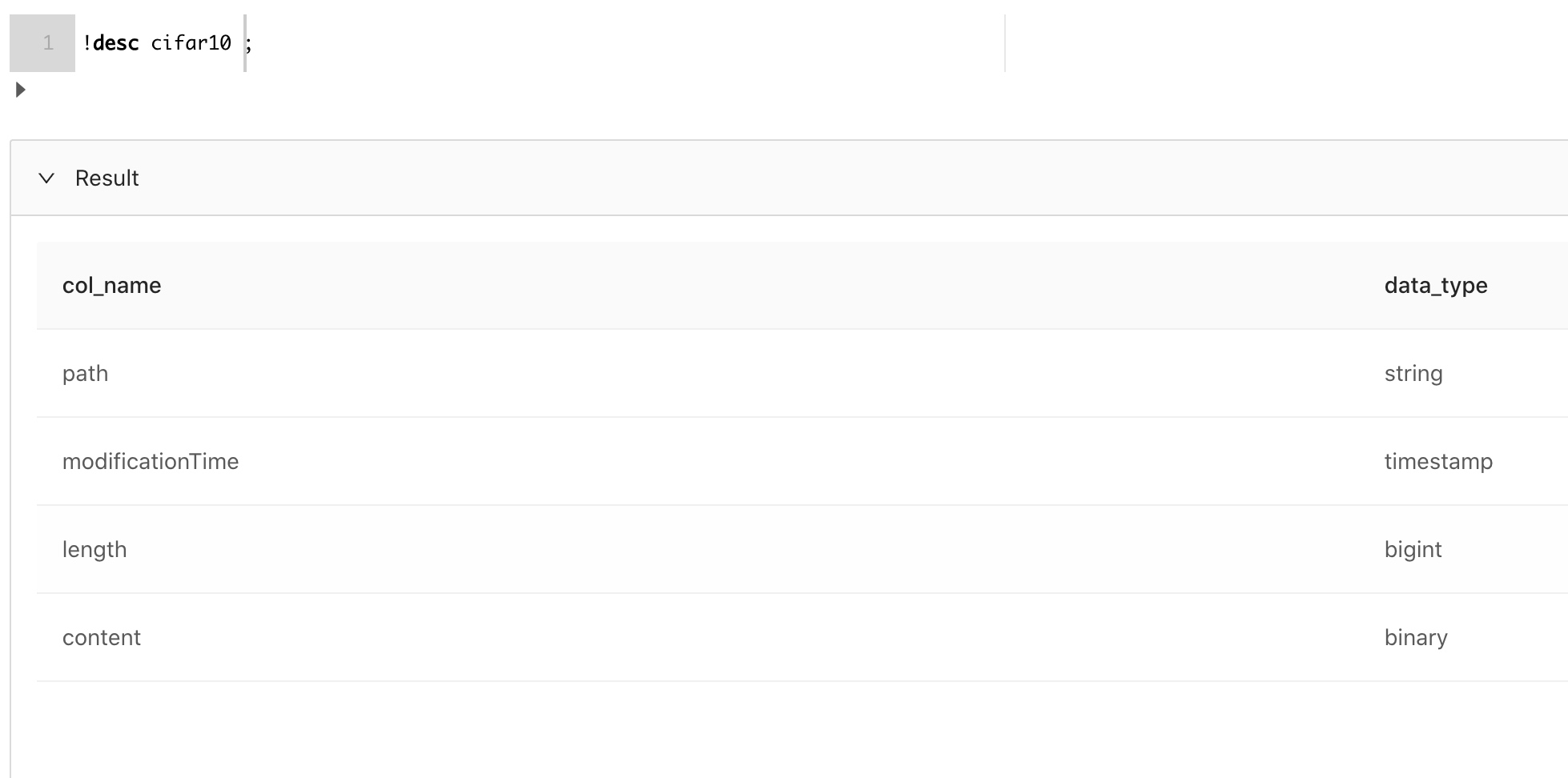
我们只关注content以及path字段,另外两个字段没什么用,可以不用。现在,可以做如下配置了:
!python env "PYTHON_ENV=source /Users/allwefantasy/opt/anaconda3/bin/activate ray1.3.0";
!python conf "runIn=driver";
!python conf "schema=st(field(content,binary),field(path,string))";
!python conf "dataMode=data";
值得注意的是,此时dataModel设置为data了,这告诉系统,我们要做分布式数据ETL了。搓搓手,我们准备用open cv来处理图片。老一套,先写几个注解,告诉当前cell是跑什么类型代码,输入输出的表是啥。
--%python
--%input=cifar10
--%output=cifar10_resize
--%cache=true
接着,我们定义一个resize_image的Python方法:
def resize_image(row):
new_row = {}
image_bin = row["content"]
oriimg = cv2.imdecode(np.frombuffer(io.BytesIO(image_bin).getbuffer(),np.uint8),1)
newimage = cv2.resize(oriimg,(28,28))
is_success, buffer = cv2.imencode(".png", newimage)
io_buf = io.BytesIO(buffer)
new_row["content"]=io_buf.getvalue()
new_row["path"]=row["path"]
return new_row
最后把方法传递给ray_context对象即可:
ray_context.foreach(resize_image)
执行下这个Cell,最后输出如下:
这个Cell完整代码在文章最后。
把处理完的图片重新保存回对象存储
正常我们可以直接把数据保存成表的。但是有的情况,我们需要把图片处理完成后,重新保存回文件系统。这可以通过如下指令完成:
我们看看最后保存的结果:
获取分类
这里我们用一些UDF函数就好了,执行效果如下:

不过我们希望能label转化为one_hot向量,这个事情也很简单。先看看分类数量:
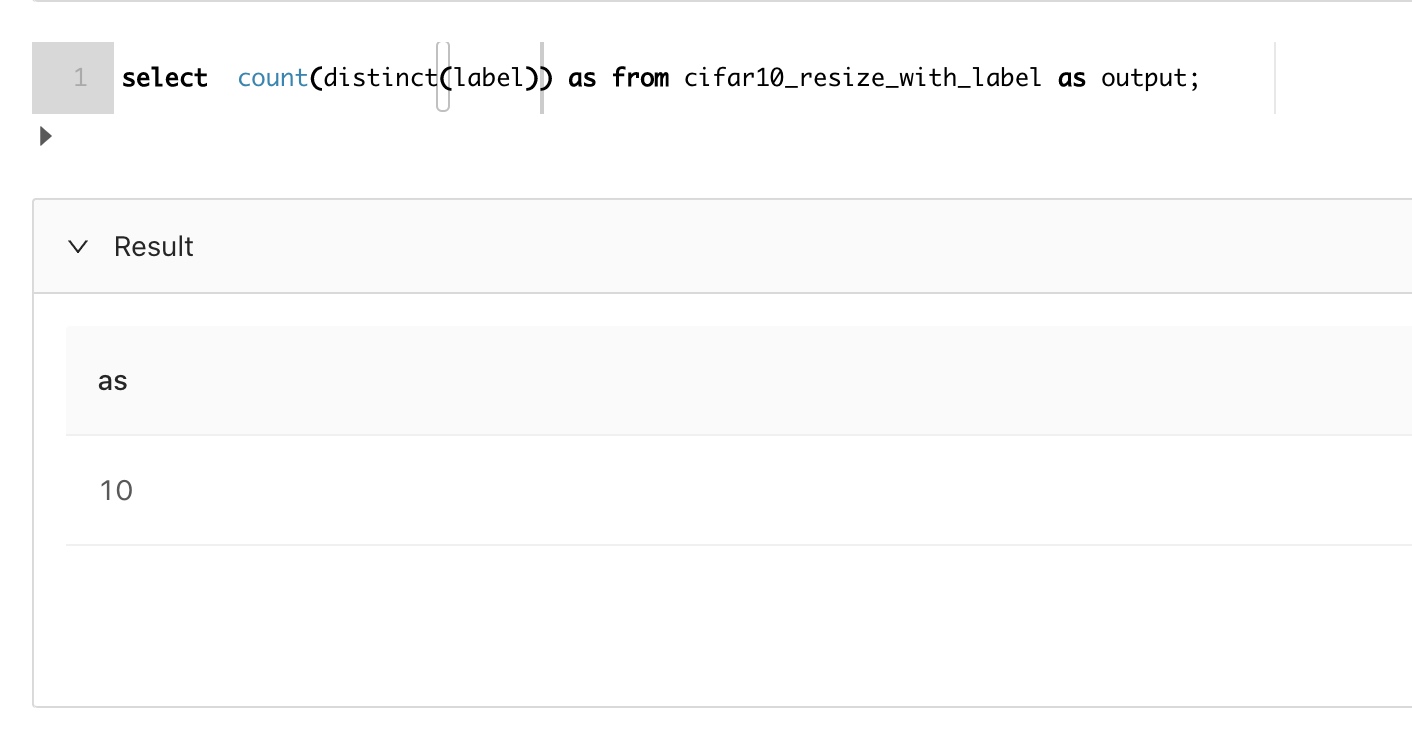
我们先把分类转化为数字:
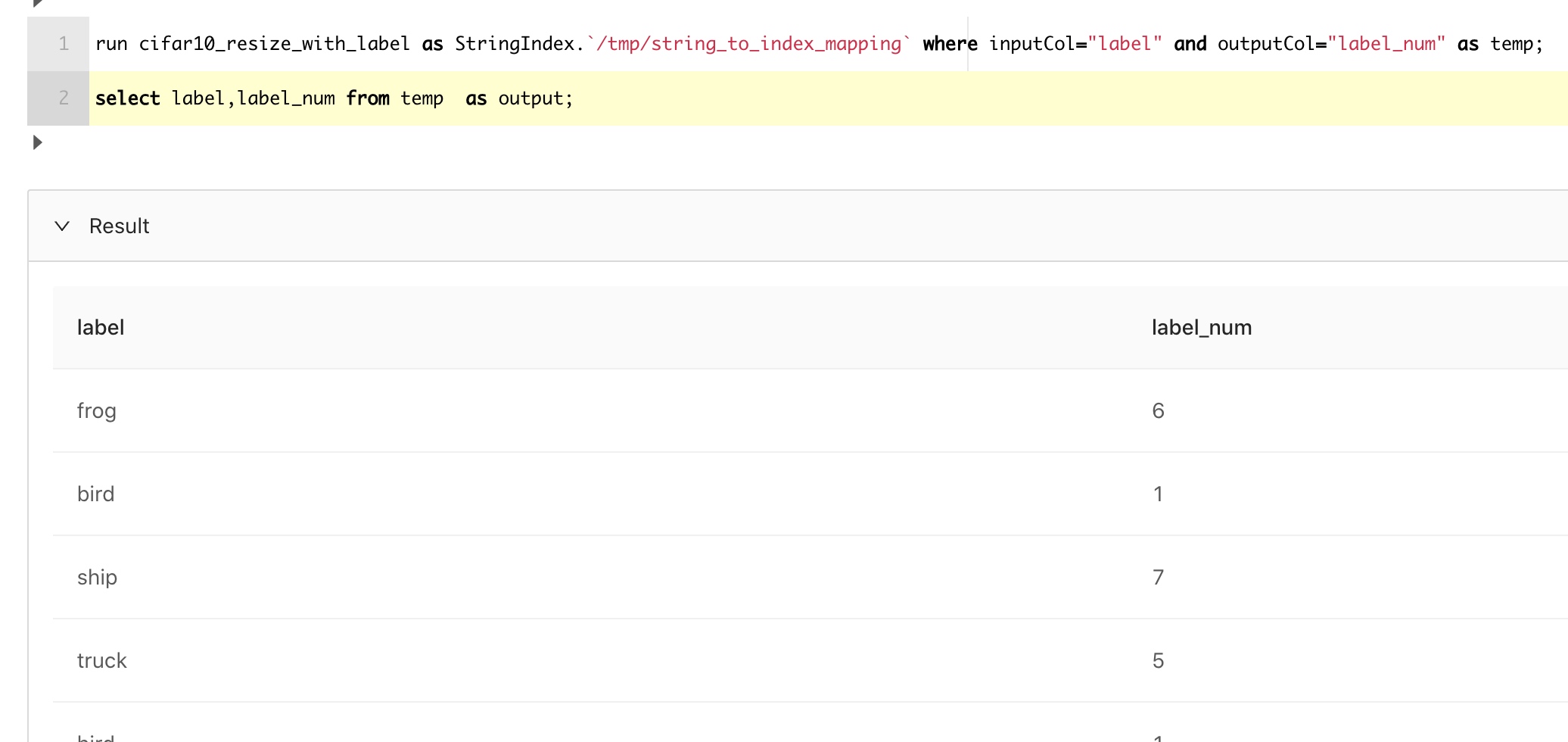
可以看到,确实做了映射了。而且这个映射关系会保存起来,方便预测的时候复用。现在使用UDF onehot就可以实现分类向量化了:
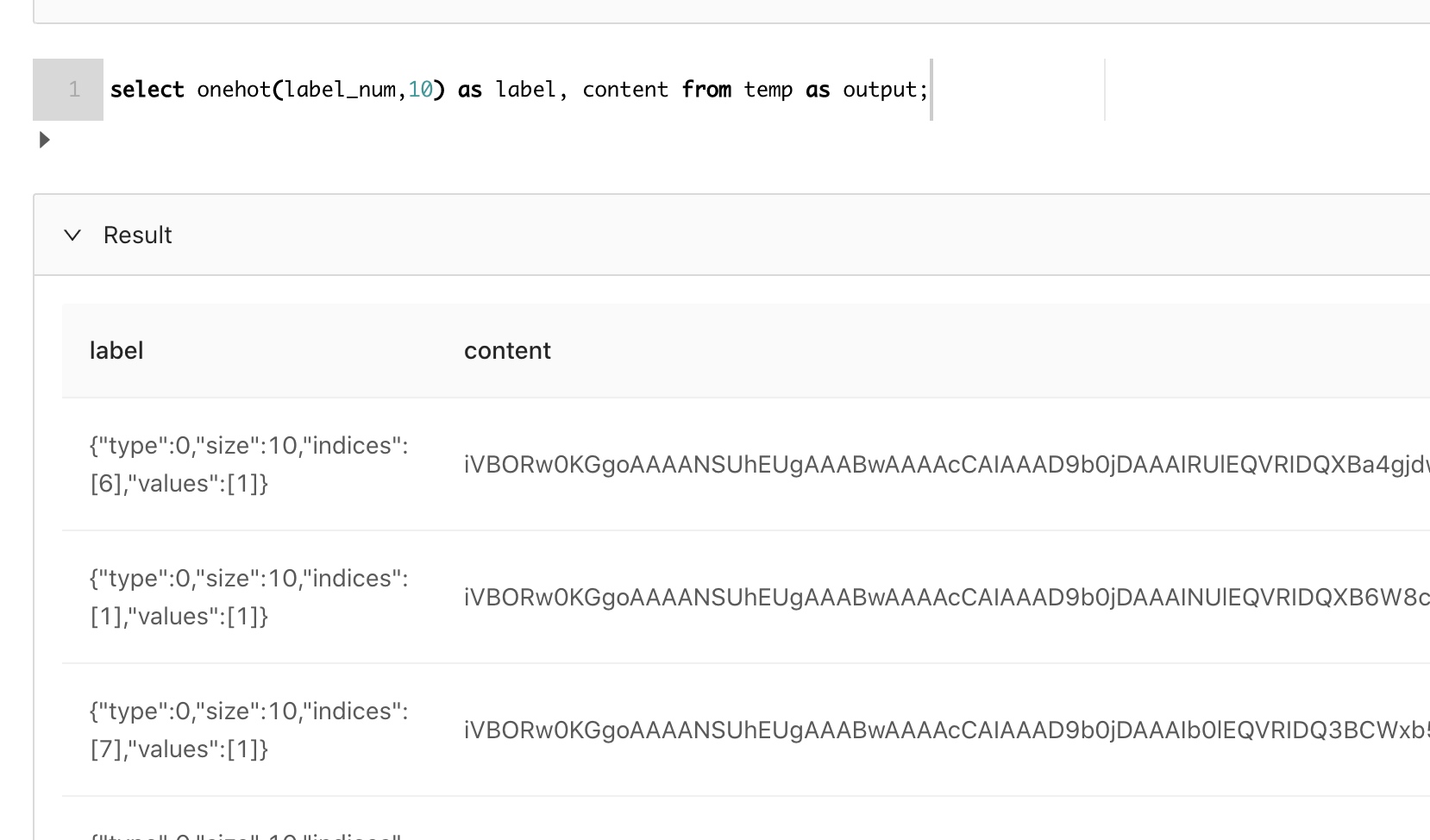
label确实已经向量化了。
拆分训练测试集合
通常我们获得数据后,还需要把数据做个拆分,做训练和预测。MLSQL也提供了模块完成这个功能。
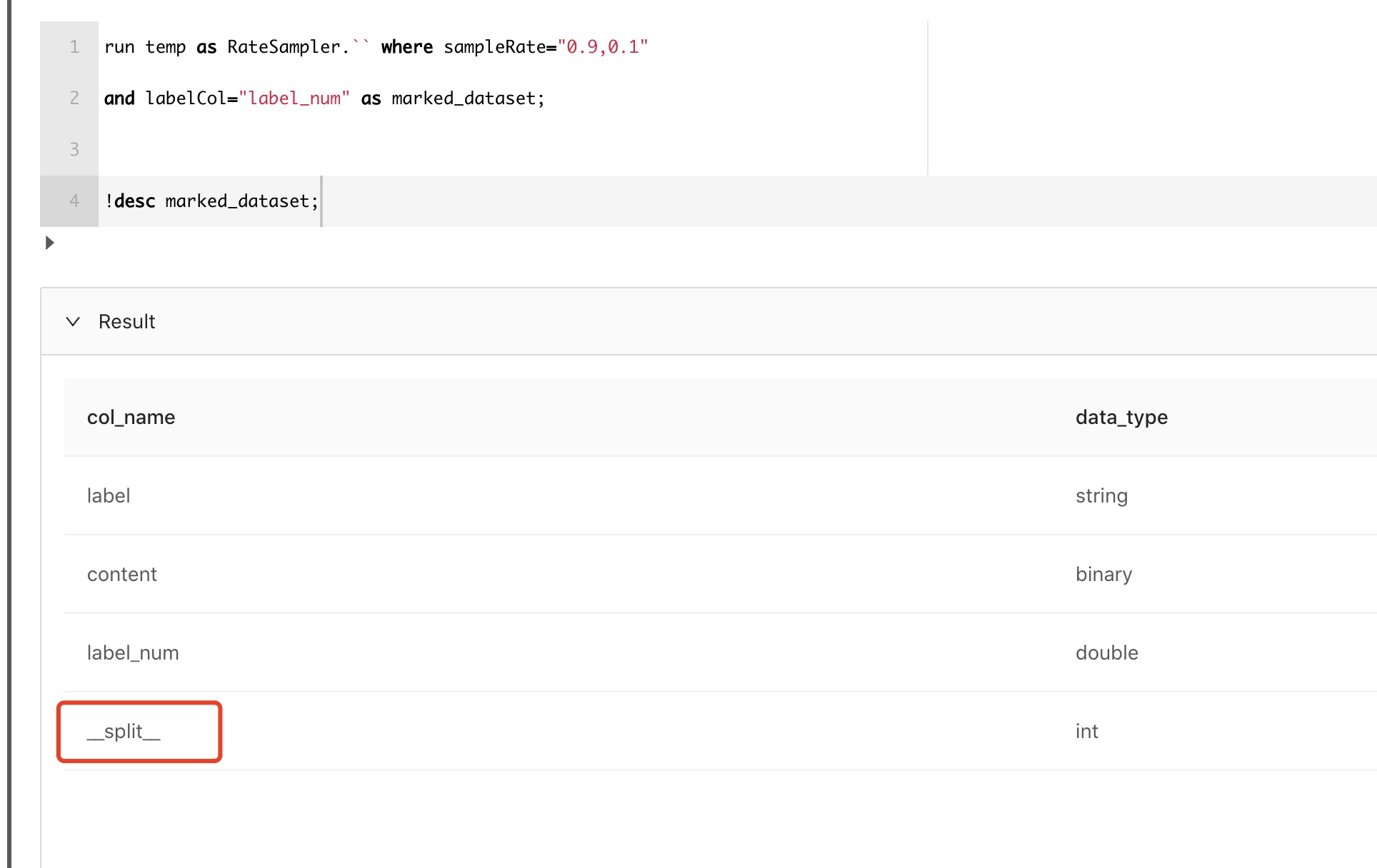
RateSampler会在表中自动添加一个叫__split__的字段, 我们在这示例里,希望切成两份数据,比例是0.9/0.1。你也可以切成任意多份。在当前示例中,然后__split__ 分别会被标记为0,1。
现在,可以分别得到训练和测试数据集了:

额外的
MLSQL大部分情况,都可以直接基于SQL UDF以及内置的SQL模块来完成特征工程,我们也提供了非常方便的能力,让用户复用Python的生态能力。在本文中,用户只要定义一个Python方法,即可实现分布式的数据处理能力,完成图片缩放的处理。
图片处理代码
#%python
#%input=cifar10
#%output=cifar10_resize
#%cache=true
import io,cv2,numpy as np
from pyjava.api.mlsql import RayContext
ray_context = RayContext.connect(globals(),"127.0.0.1:10001")
def resize_image(row):
new_row = {}
image_bin = row["content"]
oriimg = cv2.imdecode(np.frombuffer(io.BytesIO(image_bin).getbuffer(),np.uint8),1)
newimage = cv2.resize(oriimg,(28,28))
is_success, buffer = cv2.imencode(".png", newimage)
io_buf = io.BytesIO(buffer)
new_row["content"]=io_buf.getvalue()
new_row["path"]=row["path"]
return new_row
ray_context.foreach(resize_image)
完整notebook
