使用MLSQL玩转示例数据集
多亏了MLSQL 支持引用第三方项目模块,我们现在可以使用第三方示例数据模块来快速上手MLSQL语言。
我们假设你已经安装了最新的2.1.0-SNAPSHOT套件,这将分别包含console, engine两个组件。
准备数据集
首先,引入第三方模块 gitee.com/allwefantasy/lib-core,该模块要求以下Python依赖:
pip install Cython
pip install pyarrow==0.10.0
pip install ray==0.8.0
pip install aiohttp psutil setproctitle grpcio pandas xlsxwriter==1.2.0 xlrd==1.2.0
pip install watchdog requests click uuid pyjava vega_datasets plotly
我们建议使用conda进行Python环境管理。如果需要切换环境,使用如下类似命令设置:
!python env "PYTHON_ENV=source /Users/allwefantasy/opt/anaconda3/bin/activate dev";
现在引入该模块:
include lib.`gitee.com/allwefantasy/lib-core` where
alias="libCore";
接着include dataset.vega_datasets脚本:
include local.`libCore.dataset.vega_datasets`;
include后会提供一个命令供用户导出数据到对象存储上:
!dumpData /tmp/veca_datasets;
现在,可以加载并且玩转该目录下的数据了:
load parquet.`/tmp/veca_datasets` as data;
select count(*) from data as output;
可视化数据集
我们拿到这个数据集之后,就可以对这个数据集进行可视化。这里使用脚本dataset.vega_datasets_visual进行可视化。
include lib.`gitee.com/allwefantasy/lib-core` where
alias="libCore";
load parquet.`/tmp/veca_datasets` as data;
set inputTable="data";
include local.`libCore.dataset.vega_datasets_visual`;
在console执行后,可以在Tools/Dashboard- Dashboard看到可视化结果:
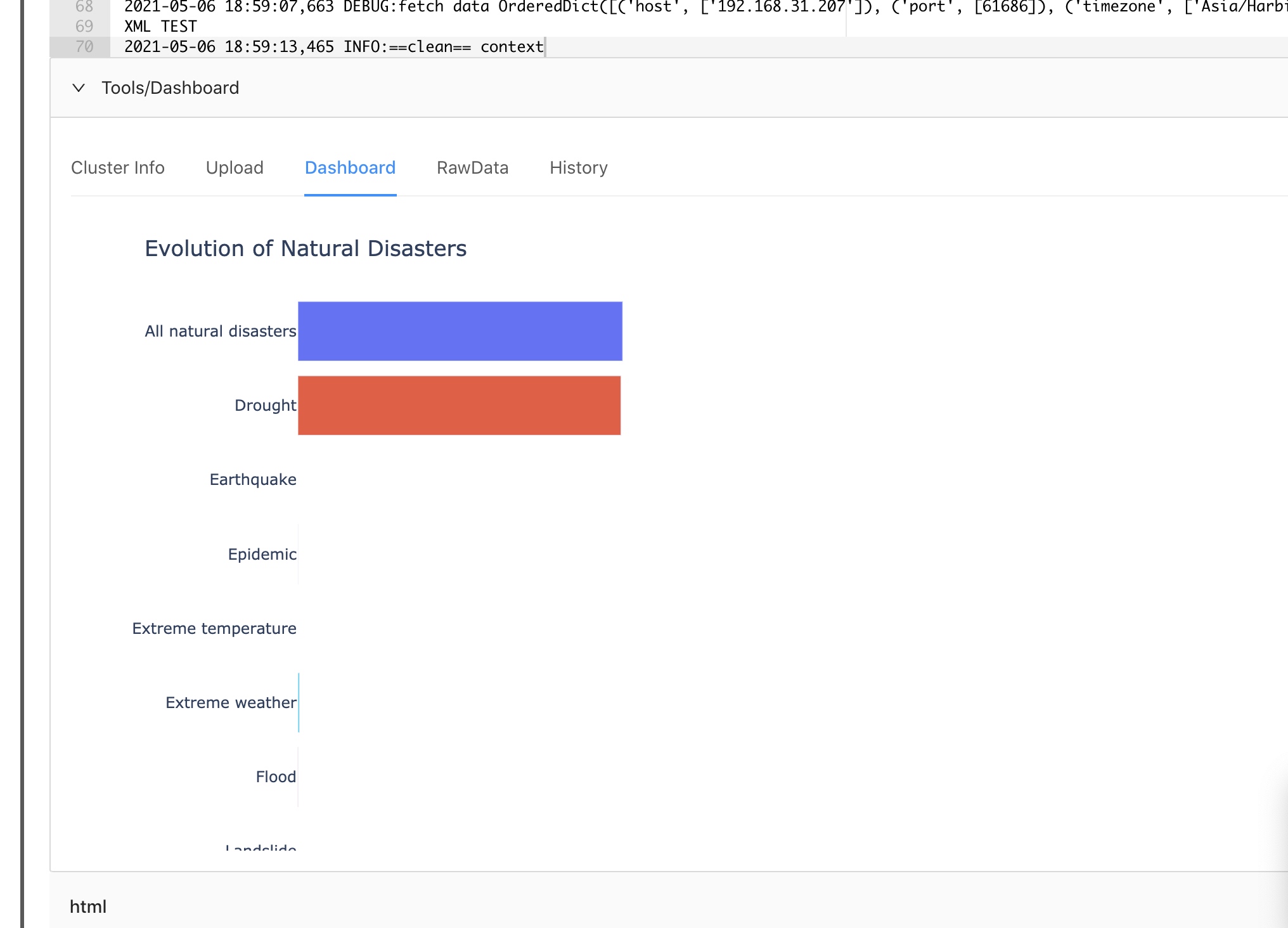
点击最下面的播放按钮,会发现这个图是个动图。
总结
后续我们会不断完善lib-core项目,提供更多有价值的示例以及实用。帮助用户快速上手以及解决实际业务问题。