谈谈MLSQL最近一些有意思的插件
MLSQL是一个插件化内核,几乎大部分扩展功能都能通过插件来完成。官方也提供了一个插件项目库 mlsql-plugins。
插件一般是使用java/scala开发的。MLSQL也支持使用MLSQL语言开发第三方库(毕竟MLSQL就是一个语言),可以参看之前的博文MLSQL 支持引用第三方项目模块。
MLSQL 插件安装
安装插件有在线或者离线两种方式。
在线安装是最简单的,只要在web console中执行 !plugin命令就可以安装。

不过这要求你是联网的。并且插件更新不一定那么及时。所以用户也可以选择离线安装。离线安装需要手动打包。以使用工具mlsql_plugin_tool 打包mlsql-shell为例:
mlsql_plugin_tool build --module_name mlsql-shell --spark spark243
这样就构建好了mlsql-shell的jar包。把jar包拷贝的MLSQL Engine包里的lib目录里(或者通过--jars手动带上)然后修改MLSQL Engine启动脚本,添加如下参数:
-streaming.plugin.clzznames tech.mlsql.plugins.shell.app.MLSQLShell
mlsql-shell
mlsql-shell是一款shell命令扩展插件。允许使用MLSQL执行shell命令。假设我们已经安装了该插件,然后我们就可以直接在Console里执行shell命令了。比如安装pyjava库,
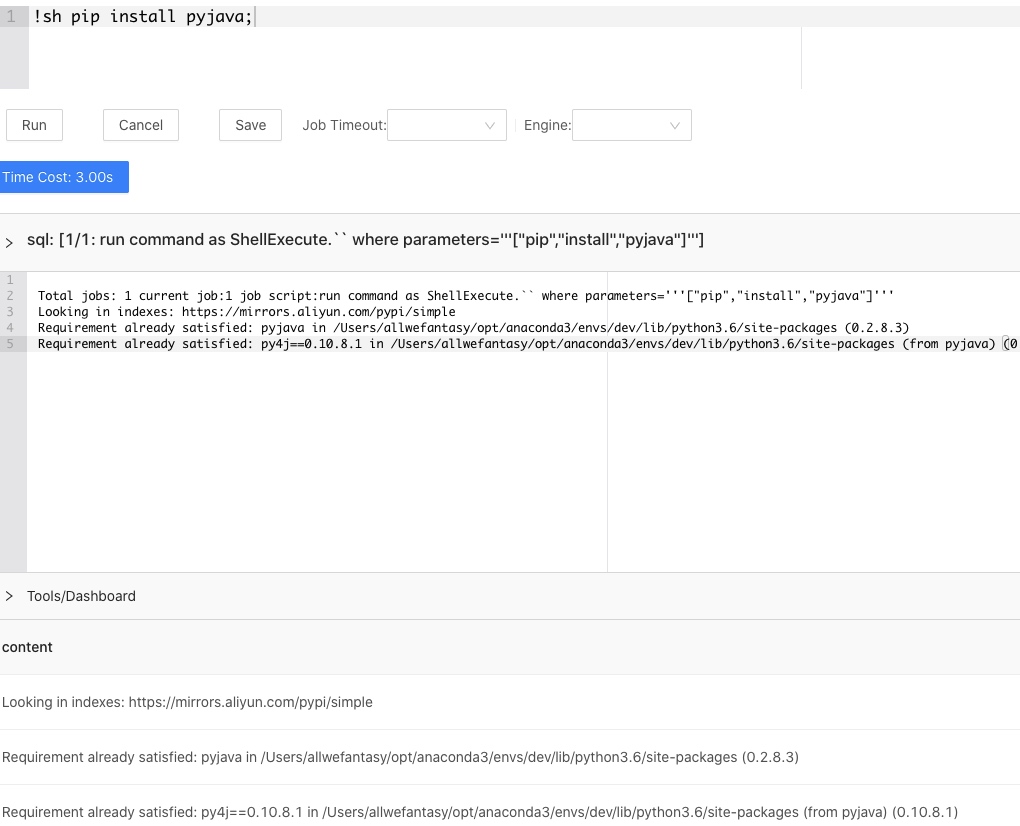
在回显窗口会实时回显这个命令的执行日志,同时在结果窗口也会执行完成后显示。
还有比如执行curl命令:

这里还有一个比较有价值的场景,如果引擎是联网的,可以直接下载文件,然后配合 !copyFromLocal 命令把文件上传到对象存储上。比如这样:
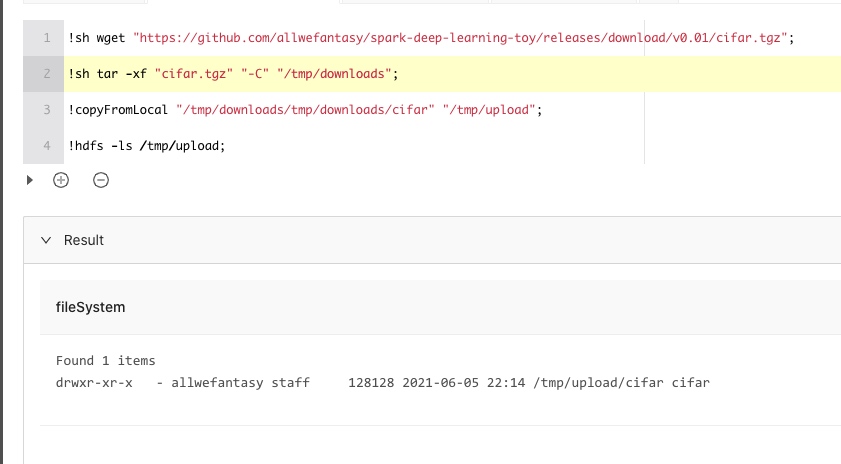
然后你就可以使用MLSQL语法对这些上传的数据做进一步复杂的处理了,比如加载图片,然后用Python处理:

mlsql-assert
mlsql-assert 有点类似单元测试里的assert, 允许你对最后的结果进行assert.这对于MLSQL黑盒测试价值比较大。用户可以比如检测最后目录是否生成,如果没有生成就抛出异常等等。还有比如MLSQL同时进行多个模型训练,然后输出的结果会告诉你那个成功,哪个失败。如果你需要确保所有的模型都全部成功,任务才算成功,这个时候就可以利用assert 检查结果。
一个比较典型的例子:
-- !plugin app remove "mlsql-assert-2.4";
-- !plugin app add - "mlsql-assert-2.4";
-- create test data
set jsonStr='''
{"features":[5.1,3.5,1.4,0.2],"label":0.0},
{"features":[5.1,3.5,1.4,0.2],"label":1.0}
{"features":[5.1,3.5,1.4,0.2],"label":0.0}
{"features":[4.4,2.9,1.4,0.2],"label":0.0}
{"features":[5.1,3.5,1.4,0.2],"label":1.0}
{"features":[5.1,3.5,1.4,0.2],"label":0.0}
{"features":[5.1,3.5,1.4,0.2],"label":0.0}
{"features":[4.7,3.2,1.3,0.2],"label":1.0}
{"features":[5.1,3.5,1.4,0.2],"label":0.0}
{"features":[5.1,3.5,1.4,0.2],"label":0.0}
''';
load jsonStr.`jsonStr` as data;
select vec_dense(features) as features ,label as label from data
as data1;
-- use RandomForest
train data1 as RandomForest.`/tmp/model` where
-- once set true,every time you run this script, MLSQL will generate new directory for you model
keepVersion="true"
-- specicy the test dataset which will be used to feed evaluator to generate some metrics e.g. F1, Accurate
and evaluateTable="data1"
-- specify group 0 parameters
and `fitParam.0.labelCol`="features"
and `fitParam.0.featuresCol`="label"
and `fitParam.0.maxDepth`="2"
-- specify group 1 parameters
and `fitParam.1.featuresCol`="features"
and `fitParam.1.labelCol`="label"
and `fitParam.1.maxDepth`="10"
as model_result;
select name,value from model_result where name="status" as result;
-- make sure status of all models are success.
!assert result ''':value=="success"''' "all model status should be success";
这里,assert 会检查result结果集里每个value值是否都为success。注意这里要求结果集不能太大,因为assert是将数据都加载到内存中进行匹配的。
mlsql-canal
社区小伙伴贡献了一个canal的插件。允许mlsql流任务直接处理Kafka中的canal数据,实时回放到数据湖表里。使用也很简单:
set streamName="binlog_to_delta";
load kafka.`binlog-canal_test`
options `kafka.bootstrap.servers` = "***"
and `maxOffsetsPerTrigger`="600000"
as kafka_record;
select cast(value as string) as value from kafka_record
as kafka_value;
save append kafka_value
as custom.``
options mode = "Append"
and duration = "20"
and sourceTable = "kafka_value"
and checkpointLocation = "checkpoint/binlog_to_delta"
and code = '''
run kafka_value
as BinlogToDelta.``
options dbTable = "canal_test.test";
''';
当然,用户也可以使用内置的spark-binlog组件完成端到端的数据实时同步。
stream-persist
MLSQL可以很方便的启动流程序,不过流程序默认是没有持久化的,如果引擎重启了,流程序并不会自动也跟着重启。这个插件就是解决这个问题的。
!streamPersist persist streamExample;
上面的命令会把指定的某个流程序,这里是streamExample 进行持久化。
此外还提供了移除,罗列已经持久化的流的信息的功能。参考插件项目页面的介绍。
mlsql-mllib
mlsql-mllib 提供了对Spark Mllib库MLSQL层的封装。目前有Evaluator的相关的功能,我们会进一步增加功能。
run-script
run-script 允许你在MLSQL脚本中执行MLSQL脚本。比如:
set code1='''
select 1 as a as b;
''';
!runScript '''${code1}''' named output;
具体有啥用,我也没想好。。。。
connect-persist
connect-persist 可以持久化connect语句,避免engine重启后connect语句信息丢失。该插件只有一个命令:
!connectPersist;
该命令持久化所有在当前引擎中执行过的connect语句。
更多
点击进入mlsql-plugins项目挑选你喜欢的插件吧。